Dans la vie, y'a 2 choses vraiment importantes.
- 1/ L'amour
- 2/ Faire des sauvegardes
Alors on va voir aujourd'hui comment mettre en place une sauvegarde d'un Linux avec upload vers Amazon S3 (mais vous pourrez aussi faire de l'upload vers FTP ou un autre serveur via SSH).
Et pour cela, on va utiliser Backup Manager. Le site officiel a disparu, mais les sources sont sur Github et apparemment toujours maintenues. Vous allez voir c'est très simple.

Placez vous dans votre répertoire home
cd ~
Et clonez le dépôt git
git clone https://github.com/sukria/Backup-Manager.git
Placez vous dedans
cd Backup-Manager
et installez Backup Manager avec la commande (vous devrez peut être utiliser sudo)
make install
Copiez le fichier de conf dans /etc/.
cp /usr/share/backup-manager/backup-manager.conf.tpl /etc/backup-manager.conf
Puis ouvrez ce fichier.
nano /etc/backup-manager.conf
On va regarder ça ensemble et je vais me concentrer uniquement sur les paramètres essentiels. Pour le reste, je vous laisserai vous documenter.
Dans la section Repository, choisissez le répertoire (BM_REPOSITORY_ROOT) où seront stockés les backups en local. Par défaut c'est /var/archives.
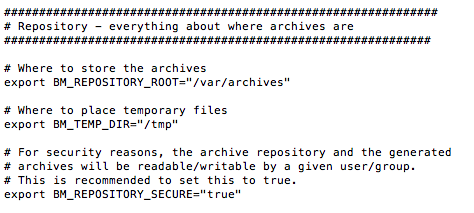
Si vous avez de la place sur votre disque à cet endroit, créez un répertoire /var/archives (mkdir /var/archives) et ne touchez pas à ce paramètre.
Concernant les backups, vous devez aussi préciser le nombre de jours que vous voulez garder (BM_ARCHIVE_TTL). Ici c'est 5 jours, mais en ce qui me concerne, je mets un peu plus, car j'ai de la place sur le disque dur.

On va ensuite choisir la méthode de sauvegarde. Vous pouvez faire uniquement un export tarball (archive simple) ou un export tarball incrémentale (archive complète + archives différentielles), un export svn, un export mysql...etc.
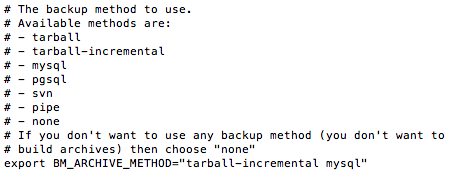
Comme vous pouvez le voir, moi j'ai mis pour le paramètre BM_ARCHIVE_METHOD : "tarball-incremental mysql"
Cela va déclencher un backup incrémental et un backup MySQL. Sachez que même si vous choisissez tarball-incremental, vous devez quand même éditer la section tarball ci-dessous.
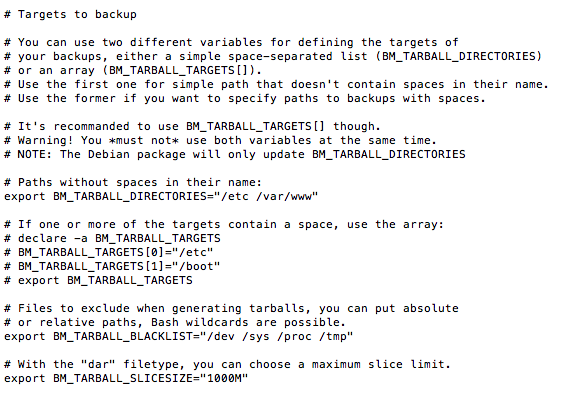
Au niveau de BM_TARBALL_DIRECTORIES, vous devez lister les répertoires que vous souhaitez sauvegarder. En ce qui me concerne, ce sera /etc et /var/www. Mais ça peut aussi être /home/ ...etc
Un peu plus bas, BM_TARBALL_BLACKLIST concerne les répertoires à exclure du backup. Cela peut être pratique si vous voulez sauvegarder tout votre répertoire /home, mais pas /home/archives qui contient vos backups ou d'autres choses dont vous n'avez pas besoin..
Enfin, BM_TARBALL_SLICESIZE permet de choisir des tailles max d'archives. Ici ce sera donc des archives de 1GB max à chaque fois.
Passons ensuite aux spécificités de l'incrémental.
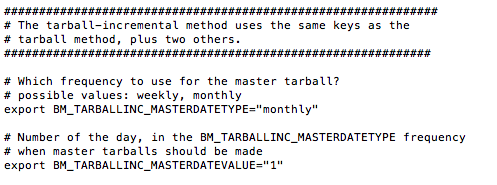
BM_TARBALLINC_MASTERDATETYPE vous permet de préciser si vous voulez une archive master par semaine ou par mois. Et ensuite de spécifier la fréquence de celle-ci (BM_TARBALLINC_MASTERDATEVALUE). Donc là, dans mon exemple, le master sera réalisé 1 fois par mois.
Passons ensuite à la conf MySQL. Ici, c'est du classique... login, mot de passe, port de MySQL...Etc
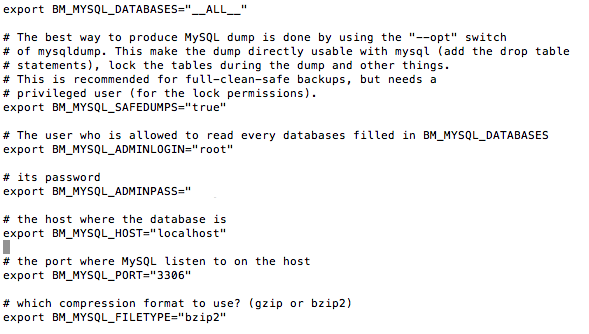
Petit parenthèse, concernant l'export MySQL, j'ai eu des petites erreurs de type
errno: 24 - Too many open files
Dans ce cas, pensez à ajouter le paramètre "open_files_limit = 3000" (je vous laisse choisir le nombre en fonction de vos besoins), dans la config mysqld.cnf et à relance MySQL.
Voilà, c'est terminé pour cette première partie. On va donc faire un test sans s'occuper de l'upload. Pour cela, mettez "none" dans le paramètre BM_UPLOAD_METHOD.
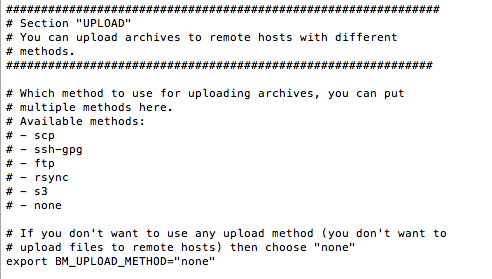
Sauvegardez le fichier, et lancez la commande
backup-manager -v
Et là, vous verrez si tout se passe bien. Si vous avez des erreurs, il y a des chances que ça concerne MySQL. Pensez à bien lire les logs d'erreur retournés pour comprendre de quoi il s'agit.
Pour surveiller que le backup est en cours, jetez un oeil dans votre répertoire /var/archives en faisant des "ls -l" à la suite pour voir la taille des fichiers augmenter.
Bon, ça, c'était le plus long à faire. Maintenant on va balancer tout ça sur Amazon S3. Vous pouvez bien sûr choisir une autre méthode d'upload comme FTP ou transfert via SSH. Et vous pouvez en mettre plusieurs... Par exemple envoyer le backup vers un FTP et vers S3.
Mettez donc le paramètre BM_UPLOAD_METHOD sur s3
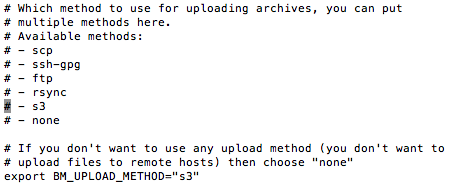
Alors concernant S3, il y a besoin de 3 paramètres :
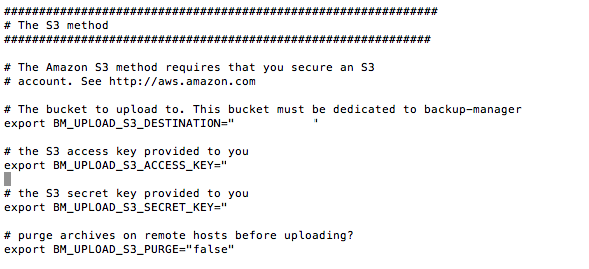
BM_UPLOAD_S3_DESTINATION c'est ce qu'on appelle le Bucket. Pas besoin de le créer en amont sur Amazon S3. Mettez ce que vous voulez et le script le créera pour vous directement.
BM_UPLOAD_S3_ACCESS_KEY et BM_UPLOAD_S3_SECRET_KEY, ce sont les identifiants S3 dont vous avez besoin. Pour cela, rendez vous ici sur votre compte S3 :
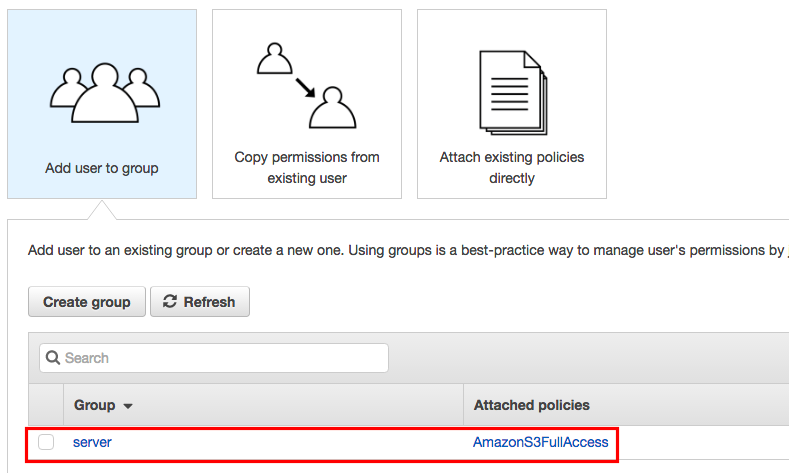
Cliquez sur Manage Users
Et ajoutez un nouvel utilisateur
Donnez lui un nom et cochez la case programmatic access.
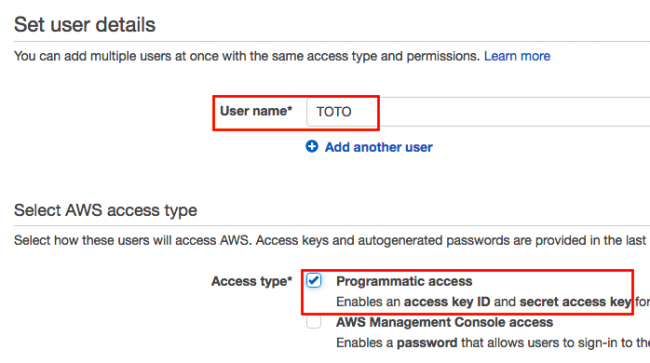
Si vous n'avez pas encore créé de groupe avec les droits sur la partie S3, faites-le.
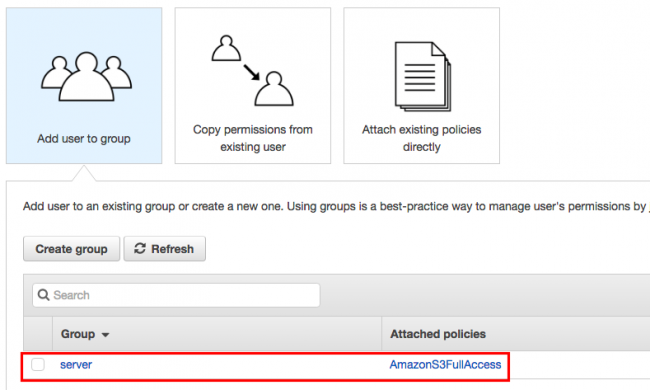
Finalisez la création de l'utilisateur
Puis récupérez l'Access Key ID et le Secret Access Key pour les mettre dans le fichier de conf de Backup Manager.
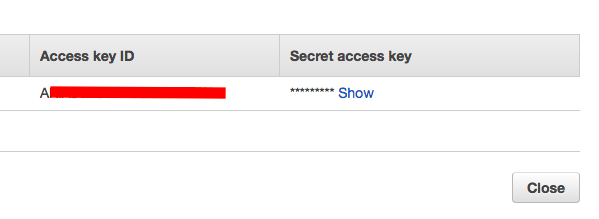
Et voilà... Maintenant y'a plus qu'à retester backup manager pour voir si le bucket est bien créé et si vos fichiers sont bien envoyés vers S3.
backup-manager -v
Comme Backup Manager utilise Perl, il est possible que vous ayez une de ce style :
Net::Amazon::S3 is not available, cannot use S3 service : Can't locate Net/Amazon/S3.pm in @INC (you may need to install the Net::Amazon::S3 module) (@INC contains: /etc$
BEGIN failed--compilation aborted at (eval 11) line 2.
The upload transfer "s3" failed.
Cela veut tout simplement dire que le module perl S3 n'est pas présent sur votre système. Faites donc un
sudo apt-get install libnet-amazon-s3-perl
Puis un
sudo cpan Net::Amazon::S3::Client
Et voilà ! Recommencez :
backup-manager -v
Normalement, si tout se passe bien, vos fichiers seront envoyés vers Amazon S3. Très bien !
Maintenant on va mettre tout ça dans la crontab pour que Backup Manager se lance tous les jours à minuit.
Lancez donc la commande
crontab -e
Et dedans, mettez
0 2 * * * backup-manager
Le 2 veut dire que ça va se lancer tous les jours à 2h du mat. Je ne rentre pas plus dans le détail car cet article est déjà assez long. Si vous voulez mettre autre chose, et que vous ne maitrisez pas la syntaxe cron, allez faire un tour sur ce site.
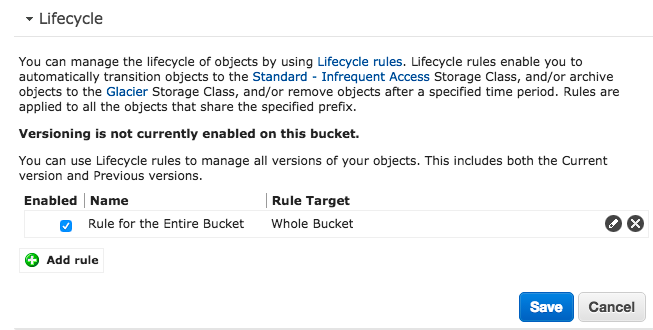
Un autre truc qui peut être intéressant aussi, c'est d'utiliser Amazon Glacier, en plus de S3. On peut par exemple directement depuis les paramètres de S3, mettre en place un cycle de vie de nos sauvegardes. Les conserver par exemple 30 jours sur Amazon S3, puis les basculer sur Glacier au bout de 30 jours et les supprimer de S3 au bout de 90. Ainsi, elles seront archivées ad vitam eternam (ou à peu près ) dans Glacier.
Si ça vous branche, voici comment faire. Placez-vous sur votre Bucket S3 fraichement créé qui contient vos sauvegardes, cliquez sur "Properties", et "Add Rule" dans la section Lifecycle.
Choisissez d'appliquer cette future règle à votre Bucket
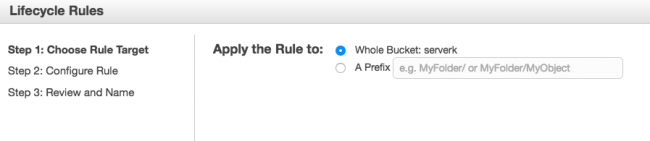
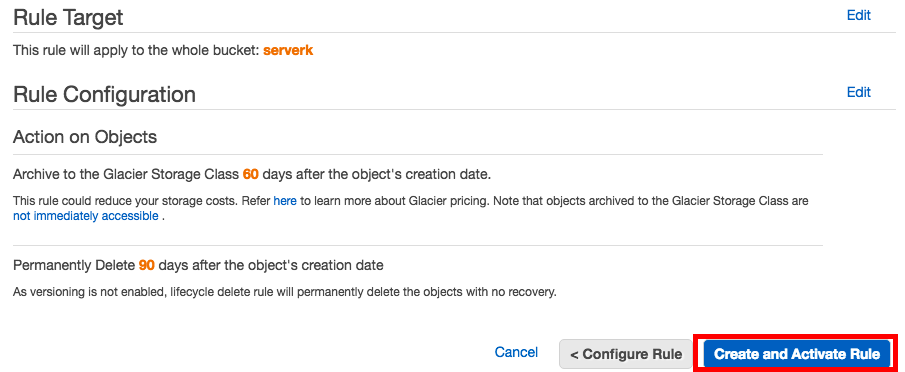
Puis c'est sur cette partie que vous devez régler le cycle de vie de vos backups. Ici, je choisis d'archiver vers glacier au bout de 60 jours et de supprimer mon archive sur S3 au bout de 120 jours.
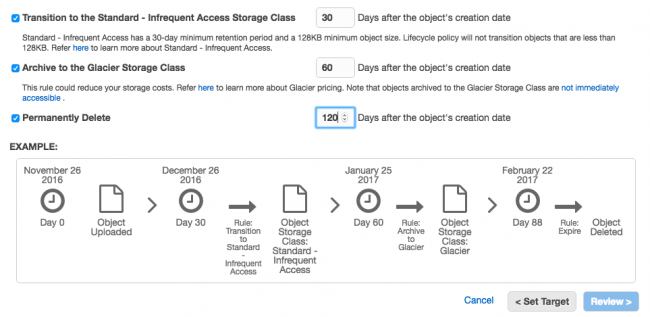
Une fois la règle créée, vous avez alors un résumé ici. Cliquez sur le bouton "Create and Activate rule".
Et voilà ! 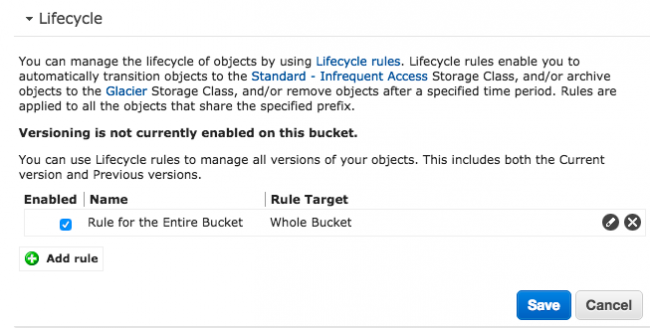
L'intérêt avec Glacier, c'est que c'est moins cher que S3 pour du stockage à long terme. Par contre, attention, si vous avez besoin de récupérer sur Glacier des archives de moins de 90 jours, vous devrez payer assez cher. Donc autant laisser une petite marge avant la suppression sur S3.
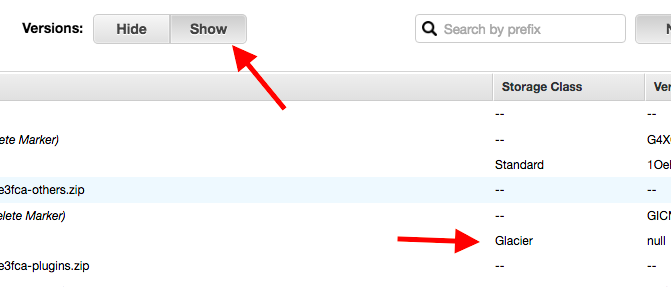
Ensuite pour voir vos backups Glacier, il vous suffira dans l'interface S3, de cliquer sur le bouton "Show".
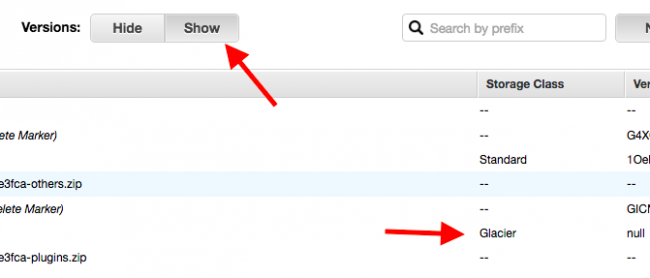
Bon, voilà, j'ai fini. Un long tuto mais un tuto indispensable car une fois encore au risque de me répéter, les backups c'est HYPER IMPORTANT.
Enfin, pour terminer en beauté, pensez à récupérer de temps en temps vos backups et en vérifier le contenu, voire à remonter une base avec et votre site pour voir si tout se déroule bien. C'est tout aussi important !
Bonne sauvegarde à tous !
Cet article merveilleux et sans aucun égal intitulé : Sauvegardez votre serveur Linux sur Amazon S3 avec Backup Manager ; a été publié sur Korben, le seul site qui t'aime plus fort que tes parents.