A Look Back at the 2020 Virtual CC Global Summit
jeudi 12 novembre 2020 à 15:011300+ participants | 200+ presenters | 170+ sessions | 60+ countries
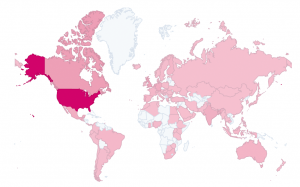
The 2020 virtual CC Global Summit exceeded our expectations—over 1300 community members, from Canada and El Salvador to Nigeria and New Zealand, chose to spend a week with us to discuss the future of open, the unknowns of artificial intelligence, the possibilities of open GLAM (galleries, libraries, archives, and museums), the pressing need for copyright reform, the impact of the COVID-19 pandemic, and much more. For the first time ever, the CC Summit was free for all to attend. We also adapted the virtual format to accommodate community members worldwide, with sessions taking place across various time zones and languages.
Facing 2020 at the CC Global Summit
When we began the journey to the 2020 CC Summit back in Fall 2019, we couldn’t have imagined the unique challenges and opportunities this year would bring. The patience, passion, and perseverance displayed by our staff, volunteers, and open community members helped create an event which aimed to, in the words of CC’s Claudio Ruiz, “find a path forward in hope and optimism.”
This year, more than ever before, we wanted the CC Global Summit to be a space that brought people together, nurtured relationships, encouraged collaborations, explored new issues, and provided a safe place for difficult questions. The response to Irene Soria Guzmán’s keynote, “Hacer feminista lo abierto: poniendo nuevos engranes a la cultura libre!” makes us believe we succeeded in that aim. Irene asked participants to look at the open movement through a feminist lens to find new ways of understanding authorship and power, creating bridges across our differences. It was encouraging to see so many community members accept her challenge with grace and enthusiasm.
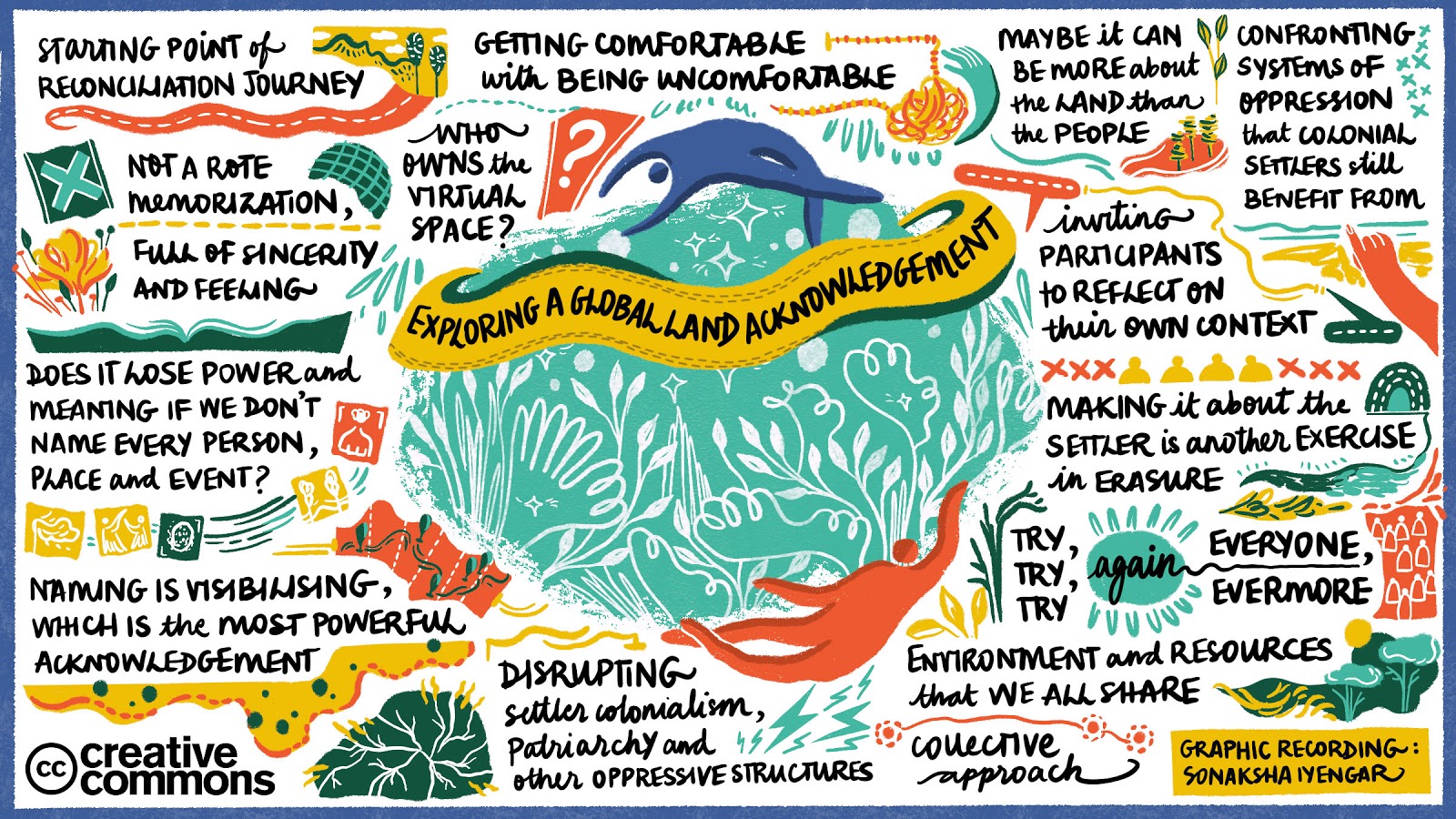
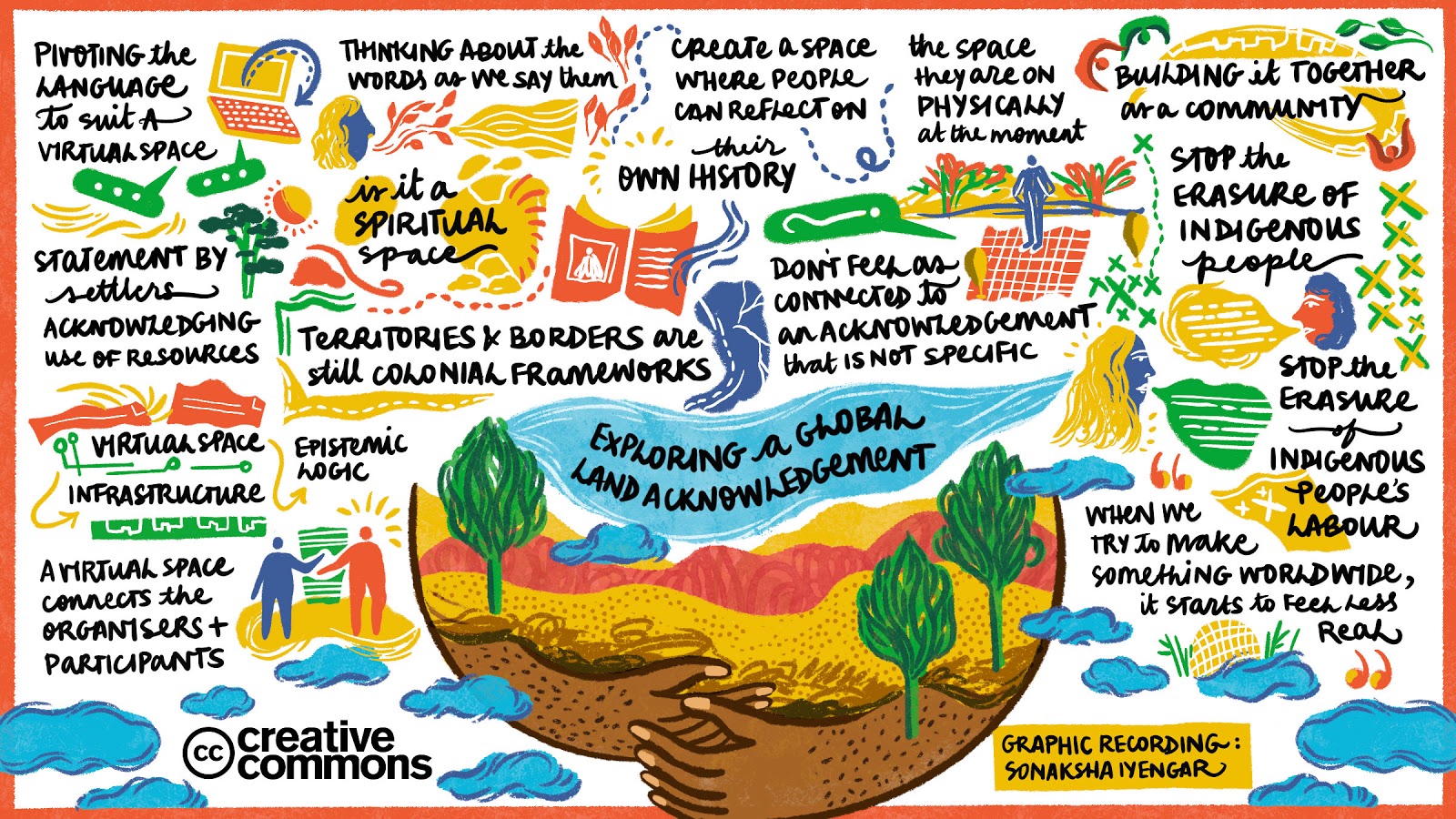
We also introduced a new session at the 2020 Summit, a global land acknowledgement, where we examined ideas of colonialism, power dynamics, and our own biases as we remixed a version for use in a virtual setting. The end result is a unique visual interpretation of those conversations by artist Sonaksha Iyengar (above).
What’s next?

Over the next week or so, we’ll be publishing all three of the CC Summit keynotes with transcripts to increase accessibility, so stay tuned! While we recorded all 170+ sessions, we plan to first receive permission from the speakers to publicly release these recordings and then create a catalog on the CC Global Summit website of the approved videos. We ask for your patience and understanding during this process, as it will take some time to ensure we respect the privacy of everyone who appeared on video. If you’re eager for video content in the meantime, check out the concert! We also released a campaign featuring the 2020 CC Global Summit artwork by Chilean artist Marco Villar. You can now purchase t-shirts, hoodies, mugs, and tote bags with this year’s artwork, and support Creative Commons at the same time! Want to make your own CC Summit-inspired pieces? Download the artwork here.
Thank you!
We’d like to extend our sincere thanks to everyone who made this event one of our best yet, despite all that’s happened in 2020. This includes the volunteers who wowed us with their energy, responsiveness, and commitment throughout the event, as well as the presenters and performers who made this event a unique and exciting adventure. Each of you gave us the insight and the opportunity to imagine what the open movement could be in the future, and for that, we are incredibly grateful.
The 2020 CC Global Summit also wouldn’t have been possible without our generous sponsors:

 As a nonprofit, Creative Commons relies on the generosity of the public to make events, like the CC Global Summit, possible. Every dollar helps us continue to unlock and expand the limits of open, driving innovation, collaboration, and creativity. Please join us in pushing the boundaries of open by making a gift to CC today!
As a nonprofit, Creative Commons relies on the generosity of the public to make events, like the CC Global Summit, possible. Every dollar helps us continue to unlock and expand the limits of open, driving innovation, collaboration, and creativity. Please join us in pushing the boundaries of open by making a gift to CC today!
The post A Look Back at the 2020 Virtual CC Global Summit appeared first on Creative Commons.