Quand la DCRI cherche à censurer Wikipedia
samedi 6 avril 2013 à 15:11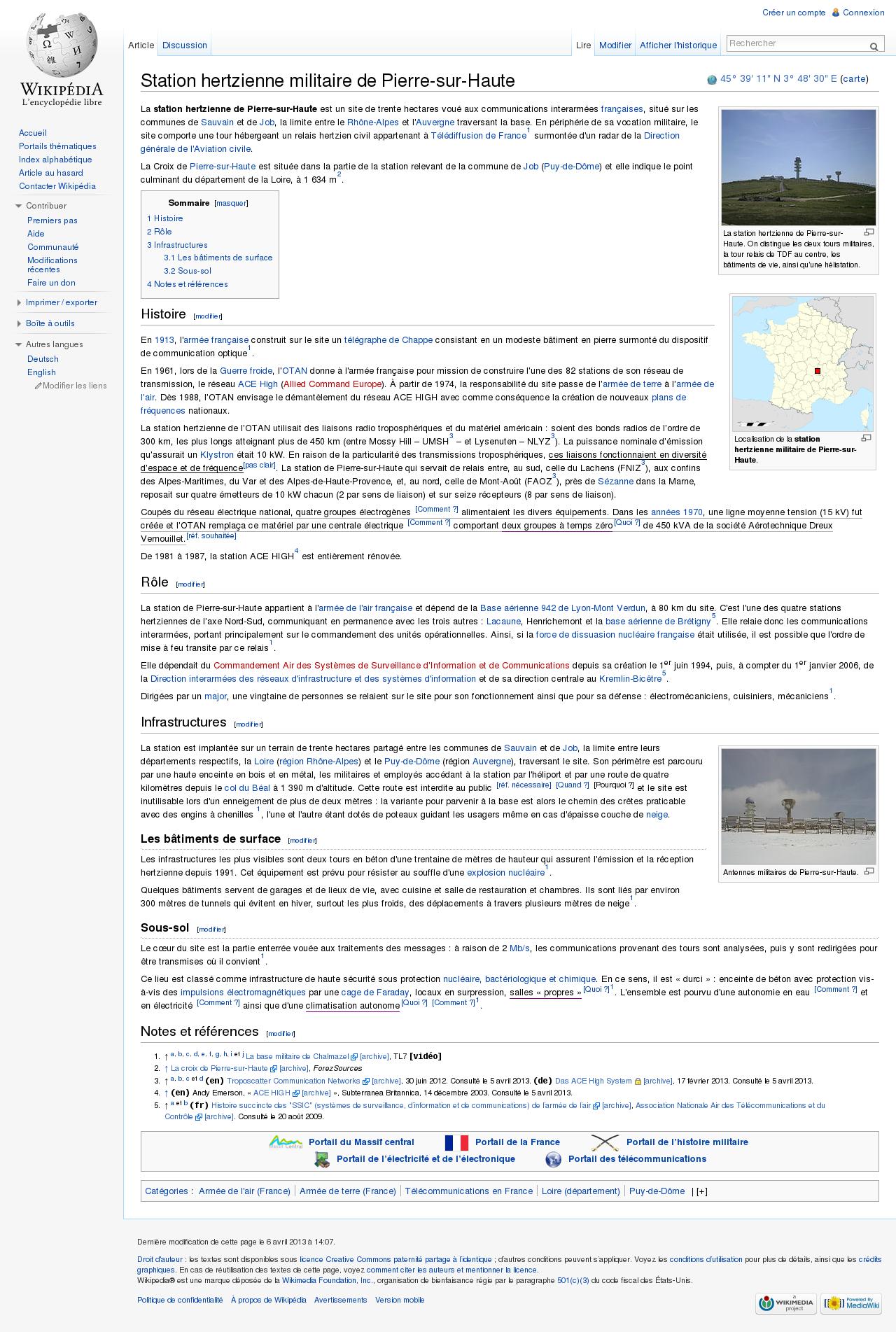
Freenet: CHK@GWwzpgiRsTrbfZrDEbBxDSMhaD0UQLafV5lko~ddDfQ,KqyqxbjViV3voMsj1XxBhQeFZpX7TpRW0xq5K-2VTnk,AAMC–8/wikitationhertziennemilitairedeierresuraute.jpg
(source: Quand la DCRI cherchent à censurer Wikipedia : les admins se dé-op… et paff l’effet Streisand)
Article de Reflets.info reproduit conformément à leurs mentions légales

La station hertzienne militaire de Pierre sur Haute est au coeur d’une polémique suite à un article probablement un peu trop bien documentée publié sur Wikipedia. La DCRI (Direction Centrale du Renseignement Interieur) n’a manifestement pas trop apprécié que l’on cause des petits dessous de l’interception.
La page créée en 2009 et qui n’avait pas été éditée depuis juillet 2012, a attitré l’attention du renseignement Intérieur en avril 2013, le 4 avril pour être plus précis.
4 avril 2013 à 11:02 Remi Mathis (discuter | contributions) a supprimé la page Station hertzienne militaire de Pierre sur Haute (Article qui contient des informations classifiées, qui contrevient à l’article 413-11 du code pénal)
22 juillet 2012 à 01:34 Duch (discuter | contributions) a automatiquement marqué la révision 81104004 de la page Station hertzienne militaire de Pierre sur Haute comme relue
Le 4 avril donc, Rémi Mathis supprime cette page au motif que cette page contrevient à l’article 413-11 du code pénal :
Est puni de cinq ans d’emprisonnement et de 75 000 euros d’amende le fait, par toute personne non visée à l’article 413-10 de :
1° S’assurer la possession, accéder à, ou prendre connaissance d’un procédé, objet, document, information, réseau informatique, donnée informatisée ou fichier qui présente le caractère d’un secret de la défense nationale ;
2° Détruire, soustraire ou reproduire, de quelque manière que ce soit, un tel procédé, objet, document, information, réseau informatique, donnée informatisée ou fichier ;
3° Porter à la connaissance du public ou d’une personne non qualifiée un tel procédé, objet, document, information, réseau informatique, donnée informatisée ou fichier.
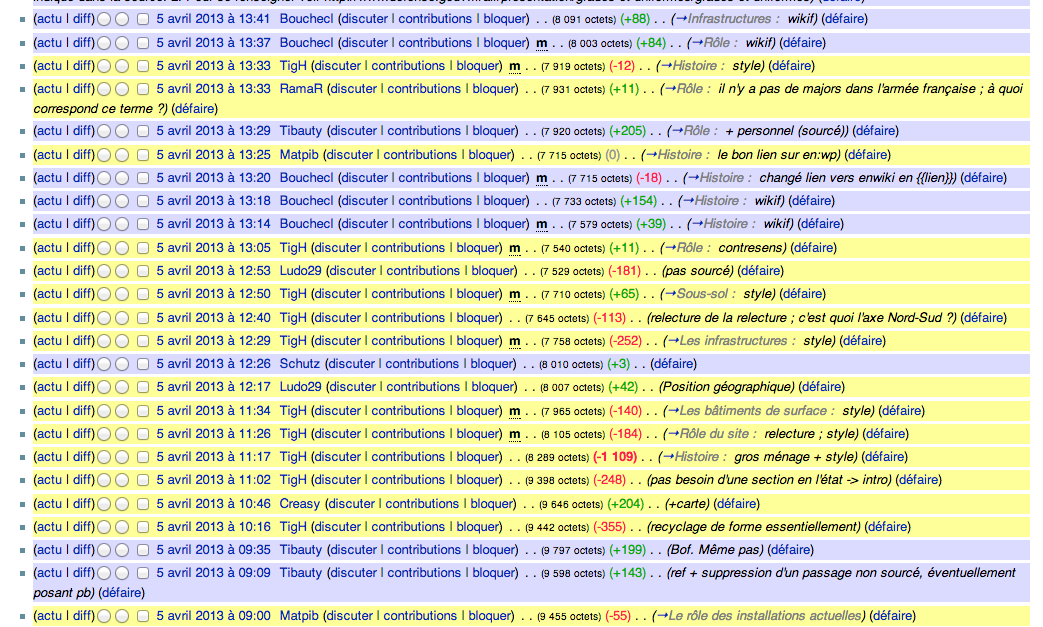
S’en suivent de nombreuses éditions de la page comme le démontre l’historique des modifications :
L’explication tombe finalement avec ce communiqué de la fondation :
Le 4 mars 2013, la Wikimedia Foundation (la « Fondation ») a été contactée par la Direction Centrale du Renseignement Intérieur (“DCRI”), une agence de renseignements française. La DCRI a affirmé que l’article “La station hertzienne militaire de Pierre sur Haute” sur la Wikipédia en français contenait des informations militaires classifiées et que la publication de telles informations violait le code pénal français, article 413-10. La DCRI a demandé le retrait de l’article dans son entièreté sans autre explication substancielle.
La Fondation a pris sérieusement ces allégations de menace de sécurité nationale et s’est renseignée sur le sujet. Cependant, il n’est pas vraiment apparent quelle information spécifique la DCRI pourrait considérer classifiée ou de risque important. Sans autre information, nous ne comprenons pas vraiment pourquoi la DCRI croit que l’information de cet article est classifiée. Presque toutes les informations de l’article sont citées par des sources publiquement disponibles. En fait, le contenu de l’article est en grande partie consistant avec la vidéo publiquement disponible dans laquelle le Major Jeansac, chef de la station militaire en question, qui donne un interview détaillé et une visite de la station au reporter. Cette vidéo est maintenant citée sur l’article. De plus, la page a été créée à l’origine le 24 juillet 2009 et a depuis lors été disponible en continu et éditée. Nous ne comprenons pas pourquoi la DCRI croit que l’article est soudain devenu une menace urgente.
Nous avons demandé plus d’informations à la DCRI, avec les phrases spécifiques ou les sections dont ils pensent qu’elles contiennent des informations classifiées. Malheureusement, la DCRI a refusé de fournir plus de détails spécifiques et a réaffirmé sa demande de supprimer l’article entier. Ainsi, la Fondation a été obligée de refuser leur requête en attendant plus d’informations que nous pourrions utiliser pour évaluer complètement leur demande.
Le 30 mars 2013, nous avons découvert que la DCRI, évidemment non satisfaite par la réponse de la Fondation, a contacté un volontaire avec des droits administratifs (un “sysop”) qui réside en France. Ce sysop n’est pas responsable de l’hébergement du contenu de Wikipédia, n’a aucun rôle dans la création de cet article, et ne fait pas partie de la Wikimedia Foundation. Tel que nous le comprenons, le sysop a essayé d’expliquer son rôle limité de volontaire et les a redirigé à nouveau vers le département juridique de la Fondation.
Malheureusement, la DCRI n’a pas accepté cette réponse et a insisté pour que le sysop utilise ses droits administratifs pour retirer immédiatement l’article, ou faire face à des représailles sérieuses et immédiates. Sous la pression de ces menaces, le sysop a retiré l’article comme demandé. Nous contactons le sysop et, s’il le désire, lui apportons notre soutien du mieux que nous pouvons faire pendant cette expérience qui peut faire peur. Nous demandons que vous respectiez sa vie privée puisque nous travaillons sur le sujet.
Il y a eu une importante discussion communautaire relatif à cette suppression et, tel que nous le comprenons, une version à jour de l’article a été par la suite réintroduite par un autre membre de la communauté.
La Fondation Wikimedia, qui maintient l’infrastructure technique de Wikipédia, aurait donc reçu une requête de suppression de la page mais aurait refusé de s’executer au motif que la demande de la DCRI ne présentait pas de motivations suffisante pour justifier un retrait. C’est suite à ce refus que la DCRI aurait alors jeté son dévolu sur Rémi Mathis qui jouissait alors de droits administrateur. Comme l’explique la fondation sur son blog, des pressions ont très probablement été exercées sur Rémi Mathis qui s’est vu retiré ses droits administrateur. Comme l’expliquent les discussions à propos de cette page, les droit lui ont été retirés pour le protéger des pression de la DCRI.
Pire, TOUS les administrateurs français ayant des responsabilités à Wikimedia France ont abandonné leurs privilèges sur le site pour éviter d’avoir à subir les mêmes pressions que Rémi Mathis… merci la DCRI, ceci est une première mondiale et c’est en France que ça se passe !
Rémi Mathis, contributeur compulsif de Wikipedia n’a pas donné signe de vie depuis jeudi soir et nous ne savons pour le moment pas s’il a été placé en garde à vue.
A l’heure où les grandes oreilles de plusieurs pays s’exposent sur Google maps, il apparait très curieux que la DCRI exerce ce genre de pression sur Wikipedia pour cette page qui ne semble pas révéler de grand secret d’état.
Ci-dessous, la station d’écoute de la DCRI située à Boullay-les-Troux.

![]()