Mise à jour
Mise à jour de la base de données, veuillez patienter...
source: blog.fevrierdorian.com
 Un peu comme Maya et son userSetup.mel, Guerilla permet d’exécuter des scripts au démarrage, mais que du lua. Voici un petit truc rapide pour exécuter du Python :
Un peu comme Maya et son userSetup.mel, Guerilla permet d’exécuter des scripts au démarrage, mais que du lua. Voici un petit truc rapide pour exécuter du Python :
Si vous allez dans le nœud Preferences, dans LocalSettings/Directories/User Plugins vous pouvez définir une liste de chemins (paths).
Sachez que tous les fichiers lua présents dans ces différents chemins seront exécutés au démarrage de Guerilla. Sachez aussi que le lua de Guerilla intègre une passerelle vers Python. Ainsi, si votre fichier lua contient :
require('python')
python.execute('import myModule; myModule.doit();')
Celui-ci exécutera le code Python :
import myModule
myModule.doit()
Vous savez maintenant comment exécuter du Python au démarrage de Guerilla ! 
 Un des premiers trucs qu’on souhaite faire quand on commence à scripter dans Maya ce sont les boutons pour exécuter nos scripts chéris.
Un des premiers trucs qu’on souhaite faire quand on commence à scripter dans Maya ce sont les boutons pour exécuter nos scripts chéris.
Naturellement, vous êtes allé dans la documentation, section Technical Documentation, puis Python Commands, avez cherché « button » et êtes tombé là-dessus. Ensuite vous êtes allé en bas de la page, vous avez copié-collé l’exemple et avez commencez à modifier votre script. Félicitation, c’est exactement comme ça qu’il faut faire. 
Sauf que comme nous allons le voir, on bute vite sur un problème. Aujourd’hui je vous propose un tutoriel pour pouvoir utiliser une même fonction appelée avec différents arguments suivant les boutons.
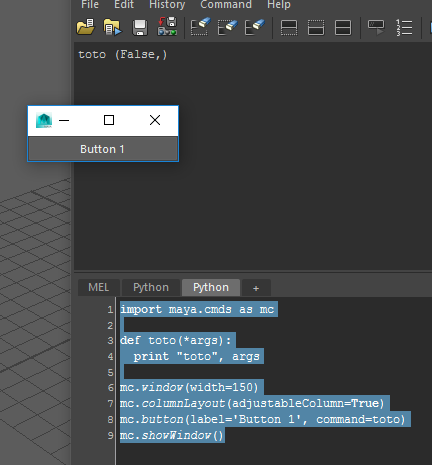
Voici une version simplifiée de l’exemple fourni par la documentation de la commande button :
import maya.cmds as mc
def toto(*args):
print "toto", args
mc.window(width=150)
mc.columnLayout(adjustableColumn=True)
mc.button(label='Button 1', command=toto)
mc.showWindow()
On va partir de la. Ouvrez votre script editor et exécutez ce magnifique script :
 Et l’explication ligne à ligne :
Et l’explication ligne à ligne :
import maya.cmds as mc
On importe le module maya.cmds sous un diminutif mc.
def toto(*args):
print "toto", args
Une fonction nommée toto qui affiche le mot « toto » ainsi que les arguments qu’on lui a passée. Pourquoi des arguments ? Je l’explique plus loin. 
Et pour la suite :
mc.window(width=150)
mc.columnLayout(adjustableColumn=True)
mc.button(label='Button 1', command=toto)
mc.showWindow()
Vous remarquerez que la fonction toto() prend des arguments. C’est assez fréquent dans les fonctions de rappel (callbacks en anglais), petit noms donné à des fonctions qui sont passées à d’autres fonctions en vu de les exécuter (ici, l’argument command du bouton, voir plus bas). Ne vous inquiétez pas avec ça pour le moment, sachez juste que, quand un bouton exécute la commande qu’on lui à donnée, il lui passe un argument, il faut donc que la fonction (ici toto()) prenne cet argument ou vous aurez un message assez clair.
Comme vous ne me croyez jamais (  ), essayez d’exécuter ça et de cliquer sur le bouton :
), essayez d’exécuter ça et de cliquer sur le bouton :
import maya.cmds as mc
def toto():
print "toto"
mc.window(width=150)
mc.columnLayout(adjustableColumn=True)
mc.button(label='Button 1', command=toto)
mc.showWindow()
Notez que la fonction toto() ne prends plus d’argument. 
En toute logique vous aurez :
# Error: toto() takes no arguments (1 given)
Le bouton a tenté de passer un argument à la fonction toto() qui a planté car, ici, elle ne pouvait recevoir aucun argument.
Bien, vous me croyez ? On peut avancer maintenant ? 
Imaginons que vous avez une fonction qui change la valeur de smooth preview sur toute la scène (au lieu de faire une sélection et d’appuyer sur 0 et 3 à chaque fois):
def smooth_preview(mode):
for mesh_node in mc.ls(type='mesh'):
mc.setAttr(mesh_node+'.displaySmoothMesh', mode)
Cette commande fait une boucle sur tous les nœuds de type mesh et met leur attribut displaySmoothMesh à la valeur du mode donné en argument.
Notez que l’attribut en question (displaySmoothMesh) ne se trouve pas aussi facilement que les autres (il n’apparait pas dans le script editor quand on le change).
Mais allez-y, essayez dans votre scène ou faites en une nouvelle :
import random
for i in range(100):
mc.polyCube()
mc.move(20*random.random()-10, random.random(), 20*random.random()-10)
Je ne résiste jamais à l’envie de faire mumuse avec le module random :

Oui, bon, je sais c’est pas l’propos mais-reuh-n'a-fout'-c'est-mon-blog-j'fais-c'que-j'veux(tm). 
Maintenant exécutez la fonction que nous avons créée précédemment avec différents modes, l’un après l’autre :
smooth_preview(2)
smooth_preview(1)
smooth_preview(0)
Et mes cubes deviennent des sphères :

Notez que la valeur ne correspond pas à la subdivision mais à un mode de preview :
Bon, c’est super, maintenant vous aimeriez que cette fonction soit appelée avec ses différentes valeurs par trois boutons. 
Assez intuitivement, vous auriez tendance à écrire ça :
def smooth_preview(mode):
for mesh_node in mc.ls(type='mesh'):
mc.setAttr(mesh_node+'.displaySmoothMesh', mode)
mc.window(width=150)
mc.columnLayout(adjustableColumn=True)
mc.button(label='Smooth off', command=smooth_preview(0))
mc.button(label='Smooth cage', command=smooth_preview(1))
mc.button(label='Smooth on', command=smooth_preview(2))
mc.showWindow()
Vous vous doutez que ça ne va pas marcher pas vrai ? 
Ne vous inquiétez pas, exécutez le script.
# Error: Invalid arguments for flag 'command'. Expected string or function, got NoneType
Bim ! 
Alors alors, que vient-il de se passer ? Le message dit que l’argument command s’attendait à une chaine de caractère ou une fonction et il a reçu un truc de type NoneType. Sachant qu’en Python, le seul truc de type NoneType c’est une variable None, il semble qu’on ait passé None à l’argument command.
Que fait exactement notre script ? En fait, il exécute les appels aux fonctions smooth_preview(0) (puis 1 et 2) et donne sa valeur de retour à l’argument command. Mais comme la fonction ne renvoie rien (il n’y a pas de return dedans), c’est comme si elle renvoyait None…
En fait, si vous reprenez votre argument toto l’argument
Mince, mais alors comment fait-on ?
C’est là que le module functools et sa commande partial() entre en jeu. 
Pour bien comprendre ce qu’on va essayer de faire, reprenons l’exemple avec la fonction toto() :
mc.button(label='Button 1', command=toto)
En fait, ici, on passe la fonction toto() à l’argument command sous la forme d’un « objet appelable » (callable object en anglais). Notez que la variable toto n’a pas de parenthèses. On passe donc la fonction toto() mais sans l’appeler. Pour imager un peu le truc : Quand on va cliquer sur le bouton, command va prendre ce qu’on lui a donné, ajouter "()" puis l’exécuter.
Et partial() là-dedans ? Il permet tout simplement de faire des « objets appelables » à partir d’une fonction et de ses arguments. Voici un exemple d’utilisation de notre cas. Essayez de l’exécuter, puis, tout particulièrement, les trois dernières lignes, une à une :
import maya.cmds as mc
import functools
def smooth_preview(mode):
for mesh_node in mc.ls(type='mesh'):
mc.setAttr(mesh_node+'.displaySmoothMesh', mode)
smooth_preview_0 = functools.partial(smooth_preview, 0)
smooth_preview_1 = functools.partial(smooth_preview, 1)
smooth_preview_2 = functools.partial(smooth_preview, 2)
smooth_preview_0() # fait exactement la meme chose que smooth_preview(0)
smooth_preview_1() # fait exactement la meme chose que smooth_preview(1)
smooth_preview_2() # fait exactement la meme chose que smooth_preview(2)
Comme indique dans les commentaires, les trois dernières lignes sont des fonctions créées par partial qui appel la fonction smooth_preview avec un argument.
On a donc créé des « objets appelables »…
La suite vous la connaissez, il suffit de passer ses objets à la commande et le tour et joue :
import maya.cmds as mc
import functools
def smooth_preview(mode):
for mesh_node in mc.ls(type='mesh'):
mc.setAttr(mesh_node+'.displaySmoothMesh', mode)
smooth_preview_0 = functools.partial(smooth_preview, 0)
smooth_preview_1 = functools.partial(smooth_preview, 1)
smooth_preview_2 = functools.partial(smooth_preview, 2)
mc.window(width=150)
mc.columnLayout(adjustableColumn=True)
mc.button(label='Smooth off', command=smooth_preview_0)
mc.button(label='Smooth cage', command=smooth_preview_1)
mc.button(label='Smooth on', command=smooth_preview_2)
mc.showWindow()
Pas vrai ?
Non en fait.  Un dernier (je vous le promets !) problème subsiste. Bon, on ne va pas vous faire exécuter le code, voici le message d’erreur si vous essayez de cliquer sur un des trois boutons :
Un dernier (je vous le promets !) problème subsiste. Bon, on ne va pas vous faire exécuter le code, voici le message d’erreur si vous essayez de cliquer sur un des trois boutons :
# Error: smooth_preview() takes exactly 1 argument (2 given)
Ça ne vous rappel rien ?  La fonction de rappel donne toujours un second argument. Il faut donc que la fonction en question (smooth_preview()) soit capable d’ingérer cet argument :
La fonction de rappel donne toujours un second argument. Il faut donc que la fonction en question (smooth_preview()) soit capable d’ingérer cet argument :
import maya.cmds as mc
import functools
def smooth_preview(mode, *args):
for mesh_node in mc.ls(type='mesh'):
mc.setAttr(mesh_node+'.displaySmoothMesh', mode)
smooth_preview_0 = functools.partial(smooth_preview, 0)
smooth_preview_1 = functools.partial(smooth_preview, 1)
smooth_preview_2 = functools.partial(smooth_preview, 2)
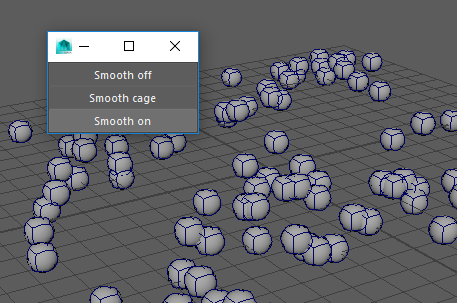
mc.window(width=150)
mc.columnLayout(adjustableColumn=True)
mc.button(label='Smooth off', command=smooth_preview_0)
mc.button(label='Smooth cage', command=smooth_preview_1)
mc.button(label='Smooth on', command=smooth_preview_2)
mc.showWindow()
Notez le *args en argument de la fonction smooth_preview().
Ne me regardez pas comme ça, vous pouvez y aller !
Allez-y, cliquez, vous l’avez bien mérité! 
Peut-être parmi vous se cache certains qui ont pu remarquer, durant ce tutoriel, un indice sur une autre façon de faire. Vous vous rappelez du message d’erreur de l’argument invalide ?
# Error: Invalid arguments for flag 'command'. Expected string or function, got NoneType
"Expected string or function"… Mhhh donc si on met des chaines de caractère (string) sur l’argument command est-ce que… :
import maya.cmds as mc
def smooth_preview(mode):
for mesh_node in mc.ls(type='mesh'):
mc.setAttr(mesh_node+'.displaySmoothMesh', mode)
mc.window(width=150)
mc.columnLayout(adjustableColumn=True)
mc.button(label='Smooth off', command="smooth_preview(0)")
mc.button(label='Smooth cage', command="smooth_preview(1)")
mc.button(label='Smooth on', command="smooth_preview(2)")
mc.showWindow()
Fichtre ça marche aussi ! 
Suis-je maso ? Méchant ? Ou tête en l’air pour être passé à coté depuis tout ce temps ? 
Non. En fait la commande button est un prétexte car :
Bref, le but était de vous montrer une fonction très utile dans un cas concret, histoire que vous sachez que ça existe et à quoi ça sert. 
A bientôt !

 Suite à la publication de mon post mortem sur Ballerina, certains d'entre vous semblaient intrigués par le paragraphe concernant l'instanciation implicite des fichiers Alembics.
Suite à la publication de mon post mortem sur Ballerina, certains d'entre vous semblaient intrigués par le paragraphe concernant l'instanciation implicite des fichiers Alembics.
Dans ce billet, je vous propose d'aller un peu plus loin avec une explication théorique, un peu de pratique et un peu de code (la recette du bonheur en somme  ).
).
Dans un fichier Alembic, les géométries sont stockées sous forme de tableaux.:
Le dernier est le plus subtil à comprendre : Combiné au second, il permet de construire les faces : La face 1 est compose de 4 indices. On prend donc, dans le tableau de position, les indices de position (dernier tableau): 0, 1, 2, 3. La face 2, est compose de 4 indices. On prend donc, dans le tableau d’indice de position, les 4 indices suivants qu’on va chercher dans le tableau des positions : 3, 2, 4, 5. Et ainsi de suite.
C’est un peu bizarre si on n’est pas habitué, mais on stocke très souvent les données géométriques de cette façon et je vais tenter de vous expliquer pourquoi. 
Vous l’aurez compris, le premier tableau ne concerne que les positions des sommets (vertices en anglais) et les deux seconds tableaux, la topologie de la géométrie. Quand un objet est animé, ce ne sont souvent que ses sommets qui bougent. Sa topologie (l’ordre de ses faces, arêtes et sommets) ne change pas.
Mais comment, quand on exporte de la géométrie image après image, la lib Alembic sait-elle que la topologie n’a pas changée ? C’est la magie des fonctions de hachage.
Histoire de vous éviter la lecture de la page Wikipédia, une fonction de hachage sert, grosso modo, à générer une signature numérique (qui ressemble vaguement à « 867fc32883baaa34 ») depuis une suite de bit.
Comme vous vous en doutez, la suite de bit en question ce sont nos tableaux. En langage bas niveau (C++ en l’occurrence), un tableau est une suite de valeur fortement typées. Un chiffre flottant se stock sur 32 bits. Une position se stocke sur 3 chiffres flottants (x, y, z), soit 3x32=96bits. Pour 8 positions (un cube) il faut donc 8x96=768bits. Ce sont ces 768bits que la fonction de hachage (Spooky de son petit nom) va ingurgiter pour nous sortir une valeur bizarre (eg. « 867fc32883baaa34 »): La signature numérique du tableau de position. Si on renvoie le même tableau (avec des positions parfaitement identiques), on a la même signature.
Vous venez juste de vous farcir un cours de science informatique en vitesse de la lumière la !
Dans un Alembic, chaque tableau possède donc sa signature numérique.
À chaque fois que vous envoyez un nouveau tableau à Alembic (pour chaque image en fait), ce dernier calcule sa signature numérique (son hash). S’il est déjà présent dans le fichier, il ne l’ajoute pas au fichier mais précise simplement que l’image en question utilise le tableau avec le hash que vous venez de calculer.
Avec ce système on peut avoir plusieurs tableaux contenant la position des sommets animés (un par image en fait) tout en gardant les deux tableaux de topologie unique pour tout le fichier.
Pour résumer, si vous exporter l’animation d’un simple cube déformé sur 10 images vous aurez :
Pour les plus curieux d’entre vous, voici la ligne de code de l’exporteur Alembic de Maya qui s’occupe d’envoyer les différents tableaux que je vous ai présenté ci-dessus dans un fichier Alembic. Notez que l’exporteur ne fait aucune distinction. Pour chaque image, il envoie tout à l’Alembic et c’est ce dernier qui décide de stocker les tableaux dans le fichier ou non.
Une fois qu’on a un beau fichier tout optimisé qu’est ce qui se passe ?
Et bien quand l’application (un moteur de rendu par exemple) demande, les tableaux de l'image 5 à un fichier Alembic, ce dernier (enfin le code de la lib Alembic) renvoi le tableau de position de l'image 5, puis les deux tableaux de la topologie de la première image.
Notez que je ne vous ai pas parlé des UVs, normals, vertex color, etc. Mais sachez que le concept est le même que pour les positions et la topologie.
Et les instances implicites la dedans ?
J’arrive au dernier point, celui qui devrait vous faire tilter. 
En plus de stocker de la géométrie, Alembic stock aussi la hiérarchie. Un transform est un objet présenté sous la forme de translation, rotation, échelle et dont la représentation mathématique est une matrice 4x4 (je ne rentre pas dans les détails mais sachez que quand vous manipulez un transform, vous manipulez en fait une matrice). Une hiérarchie de transform est donc une hiérarchie de matrice.
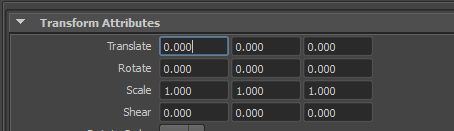
Derrière les paramètres que vous manipulez tous les jours se cache un objet mathématique bien cool: La matrice ! 
Au même titre que pour les tableaux de position et de topologie, les matrices peuvent être animé par image (quand on anim un simple déplacement qui ne déforme pas la géométrie de l’objet)
Notez que dans mon exemple précédant, j’ai précisé qu’il s’agissait d’un cube déformé. L’animation ne se situait donc pas sur le transform du cube mais directement sur les sommets (c’est la géométrie qui bouge à chaque image, comme un personnage skinné en fait).
Sauf que si, au lieu de déformer l’objet vous n’animer que son transform (translation, rotation, échelle), le tableau des positions des sommets ne change pas d’une image à l’autre, seule le transform parent de la shape (la matrice parent) change.
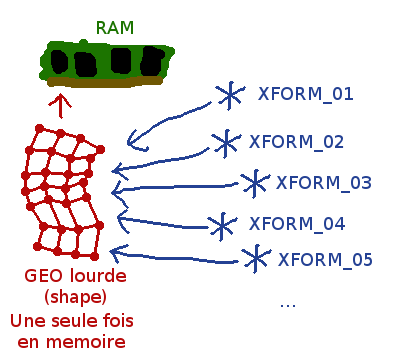
Ce qui veut dire (arriver ici vous devriez l’avoir compris) que si on modeleur duplique des centaines d’objets sans les modifier puis exporte un Alembic, les sommets et topologies des objets ne sont stockés qu’une seule fois dans le fichier et seul la position des matrices (différentes pour chaque objet) sont stockés de manière individuelle. Et ça, c’est la définition d’une instance géométrique !
Je reprends un schéma que j’avais utilisé pour expliquer le principe des instances Maya (c’est pas super adapté mais ça représente bien le principe):
Comme je sais que vous ne me croyez pas, je vous propose un exemple concret à l’aide de Maya. 
Créez une sphère :
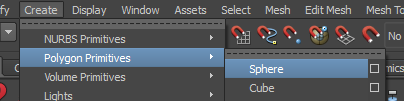

Subdivisez-la histoire qu’on puisse voir des différences de poids facilement lors de l’export :
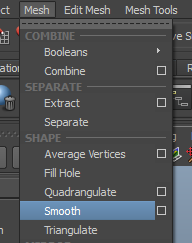

Quatre, c’est très bien :
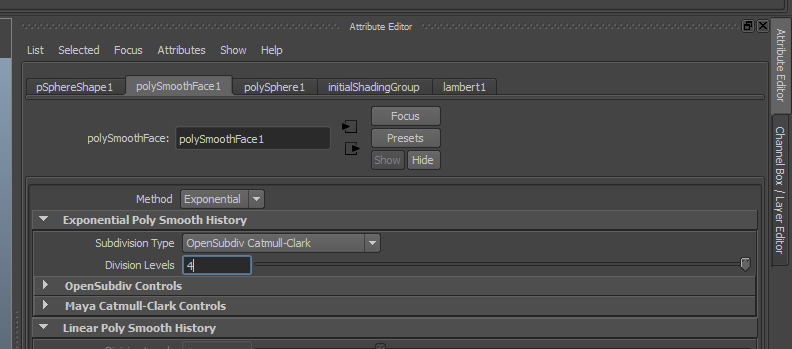

Détruisez l’historique afin de ne garder que la shape :
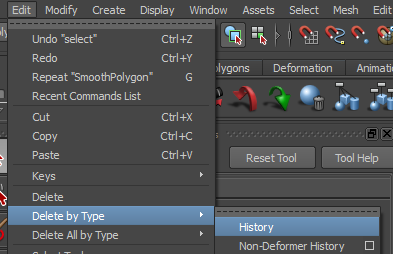
C’est parti ! Dupliquez ça plusieurs fois :

Notez qu’il ne s’agit en aucun cas d’instances Maya au sens propre. Ce sont de simple duplication. Notez aussi comment, malgré le poids de la géométrie, Maya reste réactif. Je soupçonne en effet que ce dernier utilise aussi l’instance implicite quand on fait des duplications et ne duplique la géométrie de chaque objet en mémoire qu’une fois qu’on commence à modifier l’objet.
Mais on ne s’arrête pas ! 

C’est pas mal, maintenant on exporte tout ça :
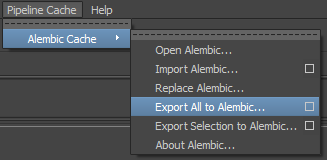
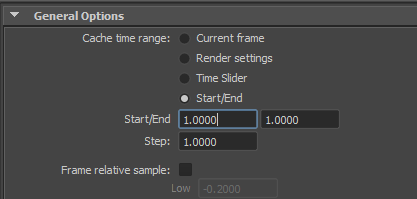
Une seule image (vous pourrez refaire le test sur un range plus large, ça ne changera pas grand-chose):
Pas besoin des normales ni des UVs :
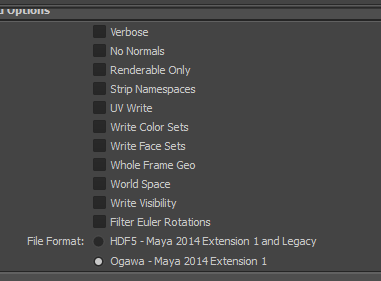
Puis validez (ou exécutez cette commande MEL):
AbcExport -j "-frameRange 1 1 -dataFormat ogawa -file /home/narann/test/test1.abc";
L’export devrait être assez rapide. Chez moi, le fichier fait 3.12Mo. Clairement, toute la géométrie n’est pas stockée. C’est parce qu’Alembic a reconnu que toutes les sphères étaient identiques. Les données qui composent sa géométrie (tableau de position des sommets et topologie) ne sont donc stocke qu’une seule fois, le reste étant des transforms (matrices) pointant vers la même géométrie.
Mais peut-être qu’avec 3.12Mo vous n’êtes toujours pas convaincu. Peut-être que 105 sphères subdivise à 4 ça ne pèse que 3.12Mo après tout…
On va donc faire un truc qui est très souvent fait en production, un truc souvent demande par le rig pour pleins de bonne raisons : On va réinitialiser les transforms. Sélectionnez tout :

Faites un "Freeze Transformations":
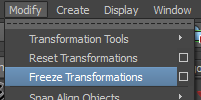
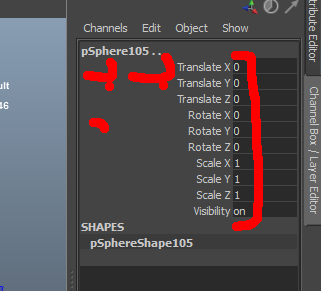
Les valeurs des positions sont donc revenus à 0 mais les centres géométriques des objets n’ont pas bouge. C’est dû au fait que Maya permet de désolidariser le point de pivot de l’objet par rapport au centre géométrique.
On va donc faire un "Reset Transformations" :
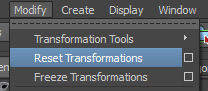
Celui-ci vient modifier les valeurs géométriques de tous les sommets pour qu’ils correspondent au point de pivot. Dans notre cas, chaque objet a maintenant son transform ainsi que son centre géométrique au centre de la scène :
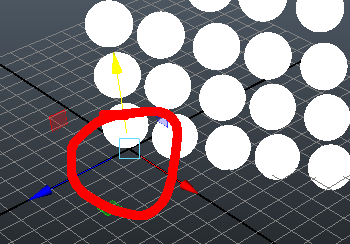
Cela veut dire que chaque sommet de chaque sphère possède une position identique à sa position dans le monde (0, 0, 0). Chaque sommet ayant une position unique par rapport à son centre géométrique, on a donc perdu toute forme d’instanciation implicite pour Alembic. Mais qu’a cela ne tienne, testez pas vous même :
AbcExport -j "-frameRange 1 1 -dataFormat ogawa -file /home/narann/test/test2.abc";
Chez moi, le fichier fait 121Mo. Chaque sphère possède ses propres tableaux de position de sommet. En principe les tableaux de topologie sont instanciés car notre petite manipulation des points de pivot n’a pas change la topologie. Si on modifiait la topologie aléatoirement pour chaque sphère, le fichier aurait été encore plus gros.
Bon, on a deux fichiers, il serait peut-être temps de les tester dans nos moteurs de rendu favoris pour savoir ce qu’il en est.
Je vais tester dans Guerilla car c’est avec lui que je suis le plus à l’aise et il dispose d’un bon retour pour savoir si l’alembic est correctement interprété.
Importez votre premier Alembic. Les applications étant souvent friandes de moyen d’optimiser le chargement des fichiers, elles s’appuient sur l’instanciation implicite que leur propose Alembic (comme expliqué dans le post mortem, ce fut flagrant sur Mari). Guerilla n’y échappe pas et c’est assez rapide :

Avant de faire le premier rendu, activez la Verbosity à Diagnostics puis cochez Diagnostic Shapes et Diagnostic Accelerator:
Puis faites un rendu. Voici le log :
06/19/2017 15:36:48 RNDR DIA: hash for 'test:pSphere61|test:pSphereShape61' is 867fc32883baaa34:60c4e1c779f31ee
06/19/2017 15:36:48 RNDR DIA: build accel 'test:pSphere61|test:pSphereShape61'
06/19/2017 15:36:48 SHAP DIA: loaded shape '/home/narann/test/test1.abc' '/pSphere61/pSphereShape61.RenderGeometry'
06/19/2017 15:36:48 SHAP DIA: P float3[99842] min=(-0.979728,-0.997817,-0.979728) max=(0.979728,0.997817,0.979728)
06/19/2017 15:36:48 SHAP DIA: N float3[99842] min=(-1.000000,-1.000000,-1.000000) max=(1.000000,1.000000,1.000000)
06/19/2017 15:36:48 MBVH DIA: Building triangle accelerator for 'test:pSphere61|test:pSphereShape61'
06/19/2017 15:36:48 MBVH DIA: Built accelerator for 'test:pSphere61|test:pSphereShape61', 199680 triangles, 8.81M (geo 3.81M, tree 5.00M)
06/19/2017 15:36:48 RNDR DIA: hash for 'test:pSphere62|test:pSphereShape62' is 867fc32883baaa34:60c4e1c779f31ee
06/19/2017 15:36:48 BRDF DIA: hash for 'test:pSphere76|test:pSphereShape76' is 867fc32883baaa34:60c4e1c779f31ee
06/19/2017 15:36:48 BRDF DIA: hash for 'test:pSphere49|test:pSphereShape49' is 867fc32883baaa34:60c4e1c779f31ee
06/19/2017 15:36:48 BRDF DIA: hash for 'test:pSphere33|test:pSphereShape33' is 867fc32883baaa34:60c4e1c779f31ee
06/19/2017 15:36:48 BRDF DIA: hash for 'test:pSphere18|test:pSphereShape18' is 867fc32883baaa34:60c4e1c779f31ee
06/19/2017 15:36:48 BRDF DIA: hash for 'test:pSphere48|test:pSphereShape48' is 867fc32883baaa34:60c4e1c779f31ee
...
Comme vous pouvez le constater, la shape n’est chargée qu’une seule fois (loaded shape dans le log) puis Guerilla s’appuie sur le hash, toujours identique, pour placer les autres sphères.
Si vous changez de fichier Alembic et que vous relancez le rendu, vous constaterez que le message de chargement de la shape « loaded shape » s’applique pour chaque sphère du fichier et que le rendu met plus de temps avant de démarrer.
Là ou c’est intéressant (et je suis sûr que tous les autres moteurs le font) c’est que quand Guerilla charge plusieurs Alembic, il instancie entre fichier. Si un modeleur a utilisé deux objets identique dans deux Alembic différents, Guerilla le remarque et ne le charge qu’une fois en mémoire. Forcément, quand tes bâtiments ne sont que des variantes de silhouette utilisant des objets géométriques identiques c’est du pain béni pour le moteur.
Si vous ne connaissez pas Python, vous risquez d’être un peu perdu sur cette dernière partie, je préfère vous prévenir. :)
Sur Ballerina nous avions une commande développée en externe qui nous permettait d’avoir le même hash que ceux qui allaient être mis généré par l’Alembic. C’est assez difficile à faire et mon but c’est de vous mettre le pied à l’étrier.
Je vous propose deux code :
Bien entendu, ce sont des codes que j’ai fais chez moi sur des scènes cubes et sphère mais absolument pas teste en production. À vous de voir ce qu’ils valent.
Voici le premier code :
import collections
import maya.cmds as mc
h_vtx = collections.defaultdict(set)
for shp in mc.ls(type='mesh'):
h = hash(frozenset(mc.xform(shp+'.vtx[*]', query = True, objectSpace = True, translation = True)))
h_vtx[h].add(shp)
Et l’explication ligne à ligne :
h_vtx = collections.defaultdict(set)
On crée d’abords un dictionnaire (defaultdict, qui permet d’ajouter un objet, ici un set, à la volée):
for shp in mc.ls(type='mesh'):
Via cette boucle nous allons traverser toutes les shapes de type mesh de la scène.
h = hash(frozenset(mc.xform(shp+'.vtx[*]', query = True, objectSpace = True, translation = True)))
Il y a plusieurs commandes empaquetées ici :
On stock le hash dans la variable… « h ».
h_vtx[h].add(shp)
Ici on ajoute la shape à la liste des shapes ayant le même hash que celui trouvé précédemment.
Imaginons une scène qui ressemble à ça (juste des sphères dupliquées avec une, au centre, dont j’ai bouge un vertex):

Si on exécute ce bout de code et qu’on print "h_vtx" on obtient :
# Result: defaultdict(<type 'set'>, {-1145497079: set([u'pSphereShape9', u'pSphereShape3', u'pSphereShape2', u'pSphereShape1', u'pSphereShape10', u'pSphereShape7', u'pSphereShape6', u'pSphereShape5', u'pSphereShape4', u'pSphereShape12', u'pSphereShape11']), 1873436783: set([u'pSphereShape8'])}) #
Le dictionnaire montre deux hashes (-1145497079 et 1873436783), le dernier n’ayant qu’une sphère, celle dont le vertex a été bouge. Vous pouvez sélectionner les sphères du premier groupe :
mc.select(list(h_vtx[h_vtx.keys()[0]]))
Modifiez 0 par 1 pour sélectionner la sphère du second groupe.
Dès lors, vous pouvez commencer à expérimenter : Dupliquer la sphère du centre (celle avec un vertex en vrac) plusieurs fois puis réexécutez le code et voyez comment il reconnait, dans le dictionnaire « h_vtx », les sphères identiques. Ensuite, faite une autre modification sur une sphère puis réexécutez le code et voyez comment cette sphère dispose maintenant de son propre hash.
Dans tous les cas, vous remarquerez que le script les regroupe bien qu’il ne s’agisse pas d’instances réelles Maya.
Arrivez ici.
Ici c’est un peu plus compliqué, mais on se rapproche beaucoup plus de ce que fait Alembic :
import maya.OpenMaya as om
sel = om.MSelectionList()
om.MGlobal.getActiveSelectionList(sel)
fn_meshes = []
for i in xrange(sel.length()):
dag_path = om.MDagPath()
sel.getDagPath(i, dag_path)
fn_mesh = om.MFnMesh(dag_path)
fn_meshes.append((fn_mesh.fullPathName(), fn_mesh))
# on aurait pu ajouter les normals, les crease edges, les colors mais osef
h_pt = {}
h_vtx_counts = {}
h_vtx_ids = {}
h_uv_counts = {}
h_uv_ids = {}
h_uvs = {}
for full_path, fn_mesh in fn_meshes:
# vertex positions
pts = om.MPointArray()
fn_mesh.getPoints(pts)
h = hash(frozenset((pts[i].x, pts[i].y, pts[i].z) for i in xrange(pts.length())))
h_pt[full_path] = h
# vertex topology
vtx_counts = om.MIntArray()
vtx_ids = om.MIntArray()
fn_mesh.getVertices(vtx_counts, vtx_ids)
h = hash(frozenset(vtx_counts[i] for i in xrange(vtx_counts.length())))
h_vtx_counts[full_path] = h
h = hash(frozenset(vtx_ids[i] for i in xrange(vtx_ids.length())))
h_vtx_ids[full_path] = h
# uv positions
uv_us = om.MFloatArray()
uv_vs = om.MFloatArray()
fn_mesh.getUVs(uv_us, uv_vs)
assert uv_us.length() == uv_vs.length()
h = hash(frozenset((uv_us[i], uv_vs[i]) for i in xrange(uv_us.length())))
h_uvs[full_path] = h
# uv topology
uv_counts = om.MIntArray()
uv_ids = om.MIntArray()
fn_mesh.getAssignedUVs(vtx_count, vtx_list)
h = hash(frozenset(uv_counts[i] for i in xrange(uv_counts.length())))
h_uv_counts[full_path] = h
h = hash(frozenset(uv_ids[i] for i in xrange(uv_ids.length())))
h_uv_ids[full_path] = h
# the hash of the hashes
h_total = {}
for full_path in h_pt.keys():
h_total[full_path] = hash((h_pt[full_path],
h_vtx_counts[full_path],
h_vtx_ids[full_path],
h_uvs[full_path],
h_uv_counts[full_path],
h_uv_ids[full_path]))
path_per_h = collections.defaultdict(set)
for full_path, h in h_total.iteritems():
path_per_h[h].add(full_path)
print path_per_h
mc.select(list(path_per_h[path_per_h.keys()[1]]))
Pas de panique, voici l’explication ligne à ligne.
import maya.OpenMaya as om
sel = om.MSelectionList()
om.MGlobal.getActiveSelectionList(sel)
Comme je n’aime pas les longs espace de nom, j’importe OpenMaya sous l’espace de nom "om".
Ensuite, on fabrique une MSelectionList qui est une sorte de « liste spécialement adaptée à la sélection ». Et on appele une commande globale bien pratique qui recupere la selection.
TL;DR: On fait l’équivalent de mc.ls(). avec plus de lignes. 
fn_meshes = []
for i in xrange(sel.length()):
dag_path = om.MDagPath()
sel.getDagPath(i, dag_path)
fn_mesh = om.MFnMesh(dag_path)
fn_meshes.append((fn_mesh.fullPathName(), fn_mesh))
Avec cette boucle, on va récupérer les MFnMesh de chacun des mesh de notre sélection. Un MFnMesh est un « ensemble de fonction » (Function set, préfixé MFn dans l’API Maya) qui permet de lier des fonctions sur des données (C’est un peu technique mais dans l’API Maya, les nœuds sont simplement des données compatibles avec certains ensemble de fonction).
dag_path = om.MDagPath()
sel.getDagPath(i, dag_path)
On crée un MDagPath vide qu’on remplit avec l’item de la sélection (« i » de la boucle). Un MDagPath est un « chemin vers un nœud hiérarchisé ».
fn_mesh = om.MFnMesh(dag_path)
Maintenant qu’on a un chemin direct, on récupère l’ensemble de fonction.
fn_meshes.append((fn_mesh.fullPathName(), fn_mesh))
Enfin, on l’ajoute à la liste sous la forme un tuple de deux éléments (le chemin du nœud et l’ensemble de fonction).
On avance dans le script pour la seconde boucle :
# on aurait pu ajouter les normals, les crease edges, les colors mais osef
h_pt = {}
h_vtx_counts = {}
h_vtx_ids = {}
h_uv_counts = {}
h_uv_ids = {}
h_uvs = {}
Ici on prépare simplement des dictionnaires de hash. Ils sont tous préfixés d’un « h_ » parce qu’ils contiennent des…? Hash bien-sur ! Vous regrettez déjà de ne pas avoir fais math sup’ math spé’ je le sais. Que voulez-vous, certains réussissent et d’autres écrivent un blog.
Bref, la clef de chacun des dictionnaires sera le chemin complet d’un nœud, et la valeur, sa valeur de hash. Un peu comme ceci :
h_pt = {'|pSphere1|pSphereShape1': 1574633,
'|pSphere2|pSphereShape2': 1574633,
'|pSphere3|pSphereShape3': 1657615,
...}
Et pareil pour les uvs…
Notez que je me suis arrêté à la géométrie et aux UVs, mais on aurait pu ajouter les normales, les couleurs par sommet, etc. Simplement que comme on ne les exporte pas avec l’Alembic : On s’en fout !
C’est parti pour la boucle principale (qui est en fait compose de plusieurs blocs assez similaires.
for full_path, fn_mesh in fn_meshes:
On déroule la boucle, pour chaque chemin complet d’un nœud on a son ensemble de fonction.
# vertex positions
pts = om.MPointArray()
fn_mesh.getPoints(pts)
h = hash(frozenset((pts[i].x, pts[i].y, pts[i].z) for i in xrange(pts.length())))
h_pt[full_path] = h
On fabrique un MPointArray() (un tableau de… MPoint()) nommé "pts", qu’on remplit avec les points du mesh via la méthode getPoints() de l’ensemble de fonction "fn_mesh".
Ensuite, on déroule les valeurs de chaque point dans un itérateur qu’on déroule à son tour, comme le script précédant, dans un frozenset() dont on génère le hash.
La raison pour laquelle on déroule la position des points c’est qu’un MPointArray() n’est pas hashable par python. Il faut donc générer une structure en pure python sinon, dans mon cas, hash renvoi toujours la même valeur, indépendamment du contenu du MPointArray(). :slowclap:
Et la dernière ligne stock le hash pour le chemin complet du nœud.
Et le reste de la boucle c’est tout pareil !
Ne change que le type des tableaux (MIntArray() et MFloatArray()) ainsi que les méthodes pour récupérer les informations (getVertices(), getUVs(), getAssignedUVs()).
Juste un petit assert (que j’utilise souvent) pour expliquer que je m’attends à ce que le tableau contenant les valeurs de U et de V fassent la même taille.
On passe à la suite :
# the hash of the hashes
h_total = {}
for full_path in h_pt.keys():
h_total[full_path] = hash((h_pt[full_path],
h_vtx_counts[full_path],
h_vtx_ids[full_path],
h_uvs[full_path],
h_uv_counts[full_path],
h_uv_ids[full_path]))
Viens l’avant-dernière boucle qui consiste, comme le commentaire l’indique, à générer le « hash des hash ». En effet, bien qu’on ait séparé les hashes par type de tableau (position des sommets, topologie, UVs), ce qui peut être très utile pour mettre le doigt sur les parties qui ne s’accommode pas aux autres, je vous propose de générer un hash final, par nœud.
On génère donc un itérateur avec tous les hash, qu’on envoie dans un hash.
Et pour finir :
path_per_h = collections.defaultdict(set)
for full_path, h in h_total.iteritems():
path_per_h[h].add(full_path)
On inverse notre dictionnaire avec, en guise de clef, le hash et en guise de valeur, un set() des chemins des nœuds avec ce hash. Ce qui nous donne un dictionnaire qui ressemble à ça :
h_pt = {1574633: set(['|pSphere1|pSphereShape1',
'|pSphere2|pSphereShape2']),
1657615: set(['|pSphere3|pSphereShape3',
...}
Et on peut sélectionner les nœuds par hash comme ça :
mc.select(list(path_per_h[path_per_h.keys()[1]]))

Conclusion
J’espère que le principe des instances implicites des fichiers Alembics est plus clair pour vous maintenant. Si vous êtes à l’aise en script, je vous invite à essayer de structurer ces informations dans une petite interface de sélection pour aider vos modeleurs. Ce n’est pas un petit boulot mais sur un projet un peu ambitieux ça peut valoir le coup.
 Je viens enfin de finir le post mortem de mon travail sur le long-métrage Ballerina. Je vous préviens, c'est long.
Je viens enfin de finir le post mortem de mon travail sur le long-métrage Ballerina. Je vous préviens, c'est long.
En espérant que ça vous plaise. 
Ce post mortem contient évidemment son lot de spoil. Je considère que vous avez déjà vu le film. Si vous ne l’avez pas fait, franchement faites-le. Le montage est rapide et on ne s’ennuie pas et vous lâcherez sûrement une petite larme. Dans tous les cas, voici la bande annonce :
J’ai eu plusieurs casquettes durant le projet (comme d’hab’ en fait…). C’était du pip’, du pip’, du pip’. Voici une liste non exhaustive de ce que j’ai fais :
Sans rentrer dans les détails, le studio appartenait aux producteurs du film. C’était leur premier long-métrage. Le projet a connu un certain nombre de difficultés et a dû “recommencer” en cours de route. Je suis arrivé alors que le projet avait été mis en pause et une bonne partir des équipes, mise à pied. Il n’y avait pas (plus en fait) d’outils, pas de pipeline. Nous n’étions pas nombreux dans le studio (moins de dix). La R&D commençait le pipeline et le département artistique continuait ses recherches. Il était d’ailleurs difficile de se dire, en arrivant le matin, qu’un film allait sortir de tout ça. La masse de travail abattu lors des premiers mois fut importante.
Le temps et les ressources disponibles étant limitées, nous avons opté pour Shotgun pour gérer l’intégralité de notre base de données (comprenez qu’il n’y avait aucune autre base de données que Shotgun, même pas un petit MySQL, planqué sur un serveur en loucedé près des toilettes, rien !). C’est (très) cher mais au vu de la configuration du studio et de ce que Shotgun propose, je pense, avec du recul, que c’était un bon choix.
Une grosse partie du travail de départ concernait les template de chemin de fichier de Shotgun pour réussir à publier en utilisant Shotgun mais notre propre structure de fichier.
Viens ensuite la suppression des step/task de Shotgun au profit d’un système maison. C’est vraiment un truc idiot, dans Shotgun, que les steps et les tasks puissent être créées et modifiées par les coordinateurs, car on ne peut, du-coup, pas s’appuyer dessus en termes d’infrastructure. Il fallait donc les remplacer pour faire la même chose mais en plus robuste.
Comme tout changeait tout le temps, les chemins de fichier n’utilisaient pas les noms des assets et des plans mais leurs ids, donnant des chemins de fichier difficile à lire. Bien que ça puisse paraître dangereux, cela n’a posé aucun soucis majeur en pratique car tout était fait pour éviter aux personnes d’avoir à naviguer dans la structure des dossiers.
Shotgun est lent. Quand le builder est arrivé (voir plus bas) on c’est retrouvé à littéralement mettre Shotgun à terre avec des requêtes importantes (en gros, notre hiérarchie de scène c’était Shotgun…). Après pas mal d’optimisation de leur part, on a aussi mis un système de cache basé sur Redis (Redis c’est bon, mangez-en).
Ces trois départements ont commencé rapidement et fonctionné en parallèle presque immédiatement, ce qui nécessitait, du fait de l’impossibilité d’anticiper, un nombre conséquent d’aller-retour. Il fallait être continuellement vigilant sur ce que chaque département livrait/récupérait. Ce fut épuisant pour tout le monde mais, et c’est peut être du fait des Québécois, personne ne râlait quand il fallait repasser sur un certain nombre de choses (chapeau aux modeleurs pour le nombre incroyable de retake techniques). Souvent nous comprenions tous pourquoi tel ou tel chose devait être modifié. L’ambiance générale était très bonne malgré les journées de travail éreintantes (c’est peut-être lié). Ça été ça pendant vraiment longtemps, doute-investigation-stresse-correction-test-avance.
Note : Il faudra que je prenne le temps, un jour, d’expliquer le principe du lighting par override. Bien que cette pratique soit très utilisée en long-métrage et série, tout le monde ne la connaît pas nécessairement.
Guerilla est un superbe outil, je le crie à qui veut l’entendre. La logique mise en place sur Ballerina a été la suivante :
Un RenderGraph initial pour mettre les paramètres par défaut. Par exemple, appliquer un shader gris-neutre sur tous les objets, assigner un shader de curve sur les objets de type curve, modifier des paramètres en fonction des tags assignés sur les objets, etc.
Le second RenderGraph était appliqué par asset. Ce sont les RenderGraphs que les artistes du lookdev faisaient et publiaient. Il assignait des séquences d’UDIM par attribut du shader (spéculaire, couleur diffuse, etc.) et modifiait les paramètres ne nécessitant pas de textures. Le tout en s’accrochant aux tags des objets.
Enfin venaient les RenderGraphs du Lighting séparés en trois : Un pour la séquence, un pour un groupe de plan et le dernier pour le plan.
Chacun de ces RenderGraph changeait (overridait) les paramètres du RenderGraph précédent.
Cette liste ne s’est pas faite d’un coup. Par exemple, les lighters ont longtemps travaillé qu’avec un RenderGraph de plan unique, les RenderGraph de séquence sont arrivés plus tard, tout comme les RenderGraph de groupe de plan arrive quasiment à la fin.
Ceci n’est pas un fournisseur d’accès internet.
On a eu de la chance (dira-t-on), Modus FX a fermé ses portes au moment où on cherchait des TDs. On c’est donc récupéré énormément de TD expérimentés. Avec le recul, il aurait été difficile de sortir le pipeline sans leur aide, ils ont vraiment fait du bon boulot. Chaque TD avait la responsabilité d’un (ou plusieurs) département mais nous codions dans le même repo git avec les mêmes standards de code. Il était d’ailleurs vraiment impressionnant de pouvoir sauter dans le code de ses collègues sans avoir l’impression d’être largué. Cette approche (très rigide à l’entrée) a réussi à créer une cohésion entre les TD qui a vraiment permise une « avancée de front ». Au passage : PEP 8 est un compromis, pas un standard.
Mon travail concernait principalement le lookdev. Nous avons utilisé Mari et Guerilla. Comme la hiérarchie n’était pas fixe, nous nous somme appuyé sur les tags. C’est un peu fastidieux et contre productif au premier abords, car les graphistes doivent placer leurs tags dans Maya, exporter leur abc et faire leur surfacing dans Guerilla. Mais il faut bien garder à l’esprit que la hiérarchie changeait constamment à cette période (rien n’était encore décidé en rig) il fallait donc trouver un moyen au lookdev de livrer sans dépendre d’autres département. Ça été, je pense, une bonne décision.
Le travail consistait grossièrement à travailler dans Mari, exécuter un script qui sortait en .tif les UDIMs des channels sélectionnés, puis faire un Update dans Guerilla qui transformait ses mêmes .tif en .tex pour le rendu. C’était fastidieux et nous aurions pu améliorer la détection des updates pour éviter beaucoup de temps perdu, notamment lors de petites retakes. Notez que seul les .tex étaient publiés. Cela n’a pas posé de soucis en pratique.
Le builder (layout), c’est la colonne vertébrale d’un pipeline d’un film. Il permet la relation entre les informations de plan en base de donne et les logiciels. Un des gros chantiers de tout long-métrage c’est la capacité à construire les plans, si possible dans n’importe quel logiciel. Je ne me suis pas occupé du Builder du côté de la base de donne, mais de son intégration dans Guerilla. C’est d’ailleurs quand les plans ont commencés à se builder sans trop de soucis que j’ai réellement pris confiance en notre capacité à sortir le projet. Tant que vous n’avez pas le moyen de reconstruire des plans, à jour, en partant de rien, vous êtes dans une situation difficile (et si vous avez des équipes qui travaillent sur des plans avant d’avoir cet outil vous êtes franchement dans la m… Ouai nan… Faites un builder avant toute chose…). Du builder découla les quality check d’animation (Ambiant Occlusion) et leur automatisation sur la render farm.
Une fois que vous avez un builder, vous construisez des plans de plus en plus gros, jusqu’à ce qu’ils ne rendent plus. L’intérieur de l’opéra (entre autre) montait anormalement en mémoire. On a donc creusé un peu pour se rendre compte que les transforms des objets était automatiquement freeze au modeling (pour une question de rig si je me souviens bien). Cela avait pour effet, lors de l’export en alembic, de casser les instances implicites.
Le principe est simple : Quand deux shapes sont identiques, on considère qu’elles sont en instance. Ce qui définit une shape c’est (entre autre) la position de ces points par rapport à son centre. Si chaque objet a un centre différent, leurs points, une fois dans l’alembic, sont à des positions différentes. Ainsi, si vous dupliquez mille fois un objet, que vous écrasez les transforms de tous les objets, chaque objet a son centre au centre du monde, et donc, chaque objet a un centre différent de celui du voisin, et donc, tous les point qui compose un objet sont différents de ceux du voisin.
Note : Maya fait une distinction entre le centre géométrique et le point de pivot. Il est donc possible de déplacer le point de pivot sans déplacer le centre géométrique.
On était très avancé en modeling, il fallait une solution simple sans trop d’intervention humaine. L’approche prise est pragmatique et pas super mathématique : On avait remarqué que la topologie des objets étaient conservés. Nous avions donc la garantie que les deux premières arêtes connectées au premier point étaient les même sur tous les objets. S’ensuit un peu d’algèbre linéaire (produit vectoriel, scalaire, merci PyMEL) et on avait une algo capable de récupérer les objets qui pouvaient être implicitement instancié et récupérer un centre identique. Une UI plus tard les modeleurs pouvaient repasser sur les gros sets pour récupérer l’instanciation implicite des objets en quelques cliques.
Il n’empêche que malgré cet outil, il fallait quand même rouvrir tous les assets pour repasser dessus. Un travail assez laborieux et ingrats. Il y eu quelques tensions autour de ça (parce qu’il a déjà fallu repasser sur presque tous les assets auparavant pour des histoires de hiérarchie). J’avoue avoir pas mal forcé auprès de la prod pour que ce soit fait. Ce n’est jamais très apprécié de faire du forcing de la sorte, mais je pense que tout le monde a bien compris qu’on allait avoir de gros soucis si on ne le faisait pas.
On a remarqué qu’en plus de diminuer drastiquement la consommation mémoire de Guerilla, les gros assets, en particulier les buildings, se chargeaient bien plus vite et étaient bien plus fluide à la navigation dans Mari.
Comme je vous le disais, le rig n’était pas défini. Il a donc fallu repasser sur tous les assets pour conformer leur hiérarchie. On a donc fait des petites boucles qui ouvraient tous les assets du film pour passer un sanity check et savoir exactement quels assets devaient être rouvert. Mais on est allez plus loin : Avec les modeleurs, on a identifié les cas de “correction scriptable” pour le faire automatiquement. Après que les modeleurs aient teste la méthode sur quelques assets, on envoyait ça sur tous les assets de la prod. Si envoyer une boucle qui ouvre tous les assets pour faire passer un sanity check n’engage à rien. Le fait de modifier, en batch, des centaines d’assets est extrêmement risqué. On a fait la procédure et le suivi à deux, l’un à coté de l’autre pendant plusieurs jours ce qui permettait une réflexion et une remise en question continue (ne jamais laisser une seule personne faire du batch qui modifie les scènes toute seul). Car derrière l’apparente simplicité, le risque de casser des centaines d’asset est réel. On a donc fait ça avec le sérieux et le professionnalisme qui s’imposait, on a relu plusieurs fois notre code, on a fait des tests et forcement, on a tout pété!
Bon, on a été malin, le commentaire de publication utilisé pour mettre à jour les assets contenait un mot très particulier. Il a donc été assez simple de rechercher les publications puis de les omettre dans Shotgun. Mais bon, je me rappelle qu’à ce moment, l’état d’esprit de la production c’était : 




Un petit fix, on a relancé la boucle et c’était bon…
Les hairs ont été faits avec Yeti. Du fait des autres chantiers, les hairs sont restés longtemps sans personne (en R&D) pour leur assurer un pipeline propre. On savait qu’on allait le payer et ça n’a pas raté. La liste des problèmes rencontrés est très longue et, il faut bien l’avouer, assez misérables. Le rig n’était pas recentre, c’est-à-dire que plus les personnages étaient loin du centre, plus la géométrie avait des problèmes de précision (J’entends souvent que « c’est le B-A BA » mais je n’ai jamais vu son application sur un long. Le rigs étant souvent trop complexe).
En pratique les soucis de précision n’auraient pas dû être un problème car dans tous les cas, nous recentrions les scènes. C’était sans compter sur la boite noire qu’était Yeti. Nous n’avons jamais eu la confirmation de quoi que ce soit (les échanges de mail étant assez improductif) mais je soupçonne que Yeti essai de se rattacher à la surface d’une distance au prorata de la densité de point. C’est-à-dire que plus il y a de point, moins Yeti va chercher la surface. Le problème que cela posait était le suivant : Afin de pouvoir générer un vecteur de motion blur, chaque point de chaque courbe qui compose les hairs doit être présent deux fois à t et t+0.5. Sauf que si Yeti n’arrivait pas à retrouver une surface lors d’un des sample, il ne calculait pas la courbe, le nombre de point devenait donc inconsistant entre t et t+0.5. Sans un nombre consistant de point, Guerilla ne pouvait générer les motion vecteur, il ne lui restait donc qu’à cacher la partie des hairs qui posait problème en affichant un warning. La solution? Recentrer les hairs avant l’export de la simulation, sauvegarder l’offset et l’appliquer dans Guerilla avant rendu B-D. Je vous passe les détails mais ça été un beau bordel. Toutefois, le truc cool en code c’est qu’à force d’effort et d’acharnement, ça finit par marcher mais ça été long et fastidieux.
Une autre de mes taches sur le projet a été de faire un outil pour gérer la végétation, en particulier les arbres et les buissons. La première question est pourquoi ne pas utiliser Yeti ? C’est difficile à expliquer si on ne sait pas comment fonctionne un pipeline. Yeti génère des .fur tout-en-un qui sont “déroulés” dans Guerilla au moment du rendu. Cette étape est très longue, la mémoire prise par Yeti lors de la génération des primitives est énorme, la bounding box est globale, l’instanciation compliquée et surtout : Une mise à jour d’un des assets nécessite un reexport du système de .fur entier. Dans une logique de pipeline d’animation, chaque département n’est supposé publier que le minimum de ce qui est nécessaire. Dans le cas de la végétation seul des informations de position/rotation/échelle ainsi que l’id de l’asset à placer (avec ses attributs de variations) sont nécessaires. Ainsi, dans Guerilla, on amène l’alembic contenant uniquement les positions des assets, la géométrie source de l’asset (que l’on cache), un script pour lier chaque position à la source et c’est terminé. On avait quelques soucis de performances, isolé dans ticket, résolu par les gars de Mercenaries (les développeurs de Guerilla) dans la semaine et on avait un système d’instance très léger, qui rendait immédiatement.
L’outil a été un peu long à écrire, mais on l’a étendu à un certains nombre de plans, notamment pour placer des personnages en instance sur les vues d’ensemble.
Mon seul regret de technophile à poil dur fut la demande de diminuer le nombre d’arbres “parce qu’il y en avait trop” alors qu’on avait virtuellement aucune limite.
La production a fait du bon boulot, car Le Petit Prince venait de se terminer et on a pu embaucher bon nombre de lighters déjà formé sous Guerilla. Je me rappelle avoir présenté le pipeline à une juniore qui, après m’avoir écouté déclarer mon amour pour les overrides, me fit comprendre qu’elle connaissait déjà tout ça. Tous les lighters étaient à l’aise avec Guerilla. Ils avaient travaillé avec une ancienne version pendants un long-métrage entier et découvrait également que beaucoup de leurs soucis avaient été résolus depuis.
On a choisi de versionner les séquences d’image de manière granulaire, à l’AOV (pass/layer/aov/<version>). Comme nous avions beaucoup d’AOV, il y avait énormément de versions à publier à chaque fois. On a fait une UI tout-en-un pour simplifier le travail de gestion des rendus des lighter (et aussi éviter qu’ils aillent se perdre et tout casser dans la hiérarchie de dossier :P). Sous le capot, l’interface était threadé à mort. Il fallait, en effet, s’assurer que le lighter voit, quand une séquence était incomplète, quelles images manquaient (et il y avait beaucoup de séquences). Le gros problème venait de Shotgun qui lâchait parfois prise et bloquait les publications sans raisons apparente, il fallait donc reprendre là ou il s’était arrêté (heureusement les cas d’arrêt pendant la copie d’une séquence d’image était rare).
Il est intéressant de constater qu’une des feature du pipeline qui permet d’économiser énormément de temps n’est arrivé que lors des six/sept derniers mois du projet. C’est quelque chose qui a été discuté très tôt, avant même l’arrivée du modeling. C’est un des trucs dont je suis le plus fier et qui a réellement augmenté la vitesse de sortie des plans. Le principe est de pouvoir overrider à la séquence mais surtout par groupe de plan. Dans la pratique, le lighter pouvait grouper les plans d’une même séquence similaires (exemple : champ/contre-champ) et appliquer des overrides pour chacun des groupes puis de propager sur toute la séquence. Ainsi, les lighter ne travaillaient plus au plan mais à la séquence. Les seniors ont rapidement sauté dessus. De manière surprenante, certains juniors ont également vite emboîté le pas. Ce n’était pas parfait, les rigs de light devaient toujours être propage manuellement et la UI de gestion des groupes n’était pas terrible, mais les séquences passaient en revu en entier très rapidement après avoir été commencé. La vitesse gagne en lighting sur certaines séquences simples était vraiment énorme.
Il y avait deux façons de publier un rendergraph de lighting : À la séquence, et au plan. Le rendergraph de plan overridant le rendergraph de séquence. L’idée était que, quand un graphiste commençait une séquence, il remonte toutes les modifications nécessaires sur toute la séquence dans le rendergraph de séquence pour ne laisser dans le rendergraph de plan que les modifications spécifiques au plan. C’est une approche assez conventionnelle quand on travaille avec des overrides, car bien souvent, le pipeline permet de publier des choses à la séquence ou au plan. Mais elle laisse un trou énorme : Que faire quand on souhaite éclairer deux plans similaires.
Si par exemple votre séquence se compose de quelques plans d’intro (souvent large), puis d’un enchainement de champ/contre champ, identique en termes de lighting, puis trois plans de sortie, vous avez 4 groupes de plan :
Chaque studio semble faire sa tambouille mais après quelques semaines de travail, on a commencé à réfléchir a un moyen de publier des choses « par groupe de plan ». Et ne croyez pas que c’est évidant. Sur un plan purement ingénierie, cette approche est « anti-hiérarchique » dans un pipeline, car si la hiérarchie « studio/projet/séquence/plan/cam » est fixe, les groupes de plan peuvent être défini différement suivant qu’on est en lighting ou en animation (ou autre). Il s’agissait donc d’une structure par séquence (il fallait bien la mettre quelque part) non connu à l’avance, donc difficilement structurable.
Les lighters avait donc moyen, par séquence, de faire des groupes de plan. Ils visualisaient la séquence et commençait déjà à réfléchir comment ils allaient publier chacun de leur rendergraph.
Au moment de construire le plan, on faisait récupérait le rendergraph publie a séquence, au plan, puis on demandait le groupe dans lequel était le plan en cours, puis on récupérait le rendergraph publie dans ce groupe. Les rendergraph s’enchainaient dans cet ordre : « sequence/shot group/shot ».
Cette méthode est arrive très tard sur le film (je dirais le dernier quart en termes de planning) mais elle a permis quelque chose d’énorme : Les lighteurs pouvaient prendre et éclairer des séquences complètes. Ça prenait un peu plus de temps de départ (compare a un éclairage au plan) mais quand ils avaient fini, ils envoyaient toute leur séquence en rendu et l’itération se faisait par séquence.
Un autre effet fut que l’éclairage était beaucoup plus cohérent entre les plans. Très souvent, les éclairages au plan tendent à casser l’homogénéité de la séquence. Ce sont les lead qui veillent constamment a l’homogénéité de l’ensemble (éclairage, couleur, etc.), mais malgré ça, ça se voit toujours. Le fait de repousser la modification par plan aussi loin que possible permettait de sucrer une bonne partie des retakes d’homogénéité. Au final, le rendergraph de plan était quasiment vide d’information d’éclairage.
J’avoue ne jamais avoir vu de système semblable aussi pousse. Bien entendu, ce n’est pas parce que je n’en ai pas vu que ça n’existe pas. Mais bien souvent ce sont des outils de propagation qui permettent d’envoyer l’éclairage d’un plan dans un autre plan, pas une publication entre la séquence et le plan.
Disons-le clairement, la gestion de la render farm n’était vraiment (mais alors vraiment) pas quelque chose qui m’attirait. Et pourtant, ça été très intéressant. Et pour cause, la render farm ne concerne pas uniquement le rendu. C’est de la puissance disponible pour de l’automatisation de tâche. Et on en a bien usé:
On a utilisé Qube. Un truc qu’il faut savoir concernant les gestionnaires de ferme de rendu c’est le “bruit réseaux” qu’ils produisent. Le nombre de machine augmentant (certaines n’étaient pas situe dans la boite mais à plusieurs une centaine de mètres du studio), il peut arriver qu’une quantité non négligeable des accès réseau ne soit prise que par le gestionnaire de ferme de rendu qui communique avec ses clients. Le problème apparaît lorsqu’il y a congestion ou chaque client a besoin de contacter le serveur sans que ce dernier ne soit capable de répondre, s’ensuit un effondrement des performances générales. Certains gestionnaires, plein de fonctionnalités qui se veulent pro-actifs (vérifier que toutes les images sont sorties, qu’elles ne sont pas corrompues, etc.) sont capables, de par leur activité, minime mais intrusive, de mettre à terre un réseau déjà bien occupé à charger des gigas de données. C’est un détail à prendre en compte quand on commence à monter en charge. Au-delà de ça, Qube a une API assez soviétique sur les bords, on sent le logiciel mature, stable et tu le payes par une API complexe.
On ne peut pas vraiment parler de pipeline pour le département de matte painting, mais de support. C’était rafraîchissant : Transfert de caméras de projection entre Guerilla et Nuke (avec ce sentiment de satisfaction quand on attend enfin le pixel-perfect). J’ai également pu constater à quel point Nuke était mauvais en 3D et à quel point un “vrai” logiciel de matte painting manquait. Je ne parle bien évidemment pas pour la peinture digitale mais pour la gestion de la 3D (projection et manipulation de la géométrie).
Sur un long-métrage, chaque plan a une histoire. Entre le nombre de département qui passe dessus (modeling, layout, animation, rendu, compositing) et les allez-retours de validation entre chaque étape, chaque personne ayant travaille sur le projet a une d’histoire à raconter. En revoyant le film, je me suis dit que j’avais envie de commenter les plans. C’est parti !
 Voici un plan typique avec des arbres et de l’herbe. Je pense qu’il y a eu une difficulte de communication autour du placement des arbres. Aucun décors breton (et français d’une manière générale) ne ressemble a ça, les arbres sont supposés délimiter les champs alors qu’ils sont placés de manière très aléatoire ici. Je soupçonne que l’esthétisme a été privilégié mais du-coup ça manque un peu de vie. Autre remarque sur Yeti : On l’a aussi utilise pour place de branches et des cailloux, mais on se retrouvait avec des bounding box énormes pour finalement peu de géométrie ce qui a pas mal ralenti le rendu.
Voici un plan typique avec des arbres et de l’herbe. Je pense qu’il y a eu une difficulte de communication autour du placement des arbres. Aucun décors breton (et français d’une manière générale) ne ressemble a ça, les arbres sont supposés délimiter les champs alors qu’ils sont placés de manière très aléatoire ici. Je soupçonne que l’esthétisme a été privilégié mais du-coup ça manque un peu de vie. Autre remarque sur Yeti : On l’a aussi utilise pour place de branches et des cailloux, mais on se retrouvait avec des bounding box énormes pour finalement peu de géométrie ce qui a pas mal ralenti le rendu.
 Le décor de l’orphelinat, l’un de mes préférés.
Le décor de l’orphelinat, l’un de mes préférés.
 Il est à noter que cette pièce est utilise à la fois pour la cuisine et pour le dortoir. Les lits remplaçant les tables. Ça passe super bien dans le film et ça a permis de se focaliser sur une seule pièce.
Il est à noter que cette pièce est utilise à la fois pour la cuisine et pour le dortoir. Les lits remplaçant les tables. Ça passe super bien dans le film et ça a permis de se focaliser sur une seule pièce.
 Je ne peux plus vérifier, mais je crois que ce plan a été rendu dans les derniers, quand la farm était quasi vide et mettait 14 h l’image
Je ne peux plus vérifier, mais je crois que ce plan a été rendu dans les derniers, quand la farm était quasi vide et mettait 14 h l’image  . Si je me rappelle bien, on savait que c’était lié à tous les rochers et branches par terre, mais on a décidé de ne pas trop chercher plus loin.
. Si je me rappelle bien, on savait que c’était lié à tous les rochers et branches par terre, mais on a décidé de ne pas trop chercher plus loin.
 La boite à musique, ou comment un plan totalement anodin peut rendre fou. Dans Maya les sous frames de l’animation étaient parfaites, mais une fois exporte en alembic puis réimporte, le motion blur explosait certaines pièces (notamment le triskèle). C’était devenu un running gag… Je ne sais même plus comment on a fini par résoudre le souci, mais je ne serais pas surpris qu’on ait totalement désactivé le motion blur 3d sur ce plan.
La boite à musique, ou comment un plan totalement anodin peut rendre fou. Dans Maya les sous frames de l’animation étaient parfaites, mais une fois exporte en alembic puis réimporte, le motion blur explosait certaines pièces (notamment le triskèle). C’était devenu un running gag… Je ne sais même plus comment on a fini par résoudre le souci, mais je ne serais pas surpris qu’on ait totalement désactivé le motion blur 3d sur ce plan.
 Les escaliers sont souvent une tanne à rendre, mais je trouve que l’épique lighting s’en est sorti à merveille.
Les escaliers sont souvent une tanne à rendre, mais je trouve que l’épique lighting s’en est sorti à merveille.
 J’adore cette séquence de nuit. Le fait d’avoir une seule source principale de lumière (celle de la moto) donne à la séquence un aspect dramatique. Encore une fois, je pense qu’on a trop négligé le placement des arbres, ça manque de vie.
J’adore cette séquence de nuit. Le fait d’avoir une seule source principale de lumière (celle de la moto) donne à la séquence un aspect dramatique. Encore une fois, je pense qu’on a trop négligé le placement des arbres, ça manque de vie.
 Notez le renfoncement de la route sur toute cette séquence. L’objectif, vous vous en doutez, est d’éviter d’avoir à travailler l’horizon sur l’ensemble des plans.
Notez le renfoncement de la route sur toute cette séquence. L’objectif, vous vous en doutez, est d’éviter d’avoir à travailler l’horizon sur l’ensemble des plans.
 Et voila un keyshot. Le principe d’un « keyshot » (ou « plan-clef ») sur un long-métrage (et en animation 3d d’une manière générale) est de valider l’éclairage type d’une séquence (couleur, ombres et tout ce qu’il est possible de définir dès cette étape en fait). Ils sont donc souvent plus travaillés que les autres et permettent aussi de mettre le doigt sur les problèmes technique avant d’entamer le travail à la séquence. Ce sont souvent les seniors qui font ses plans. L’objectif est de se représenter l’intégralité de la séquence et comment tous les plans vont être fait et de « passer la main » aux graphistes juniors qui (en principe mais là on rêve un peu) ajuste un éclairage donne sans se prendre la tête.
Et voila un keyshot. Le principe d’un « keyshot » (ou « plan-clef ») sur un long-métrage (et en animation 3d d’une manière générale) est de valider l’éclairage type d’une séquence (couleur, ombres et tout ce qu’il est possible de définir dès cette étape en fait). Ils sont donc souvent plus travaillés que les autres et permettent aussi de mettre le doigt sur les problèmes technique avant d’entamer le travail à la séquence. Ce sont souvent les seniors qui font ses plans. L’objectif est de se représenter l’intégralité de la séquence et comment tous les plans vont être fait et de « passer la main » aux graphistes juniors qui (en principe mais là on rêve un peu) ajuste un éclairage donne sans se prendre la tête.
 Le train a été utilisé pour faire quelque chose d’assez peu courant (longue explication en approche): Sur ce projet, le layout avait la possibilité de bouger les contrôleurs de certains objets des assets pour éviter la répétition. Un bon exemple sont les volets des maisons, les portes, les tables, etc. Le problème c’est que du-coup, les assets en questions ne sont plus vraiment en position d’origine ce qui est assez problématique, car vous ne pouvez plus simplement considérer, dans votre base de donne, qu’un shot contient une instance d’asset place a tel endroit, il faut aussi avoir la liste des modifications de placement quelque part. Très souvent (enfin j’ai vu ça partout jusqu’à présent), la solution retenue face à ce dilemme est : « Si ce n’est pas juste un déplacement du contrôleur global, c’est de l’animation » et donc, c’est exporté avec l’alembic d’animation du plan (qui contient les personnages et les props déplacés). Mais avouez que c’est bête d’imposer l’export par plan d’un asset au complet quand seul un des objets qui le compose (un volet, une porte, etc.) est modifie… On a donc décidé de se lancer dans une quête un peu folle consistant à récupérer les modifications de placement des sous objets au layout pour pouvoir les appliquer sur l’asset original lors de la construction du plan au rendu. Pour être honnête, on eut pas vraiment le choix, le layout avait fait un gros travail de placement (il y a des contrôleurs, ils les bougent, c’est normal) quasiment plus aucun asset ne correspondait a sa position d’origine… Il fallait donc, pour les assets en questions, stocker la position des objets qui ne sont pas à leur placement d’origine. Sauf qu’il peut y avoir une différence entre le placement d’un contrôleur (que le layout déplace) et le placement de la géométrie qu’il contrôle. Le rig garantie (en principe, mais ce n’est pas le problème ici) que la relation de position entre un contrôleur et la géométrie qu’il contrôle est toujours la même. Mais il ne garantit pas que l’origine de la géométrie en question soit constante entre les versions de rig. Pas grave me diriez-vous, c’est pas le truc qui change souvent… Et devinez quoi ? Oui, c’est ce qui c’est passé, l’origine des géométries bougeait entre les versions de rig
Le train a été utilisé pour faire quelque chose d’assez peu courant (longue explication en approche): Sur ce projet, le layout avait la possibilité de bouger les contrôleurs de certains objets des assets pour éviter la répétition. Un bon exemple sont les volets des maisons, les portes, les tables, etc. Le problème c’est que du-coup, les assets en questions ne sont plus vraiment en position d’origine ce qui est assez problématique, car vous ne pouvez plus simplement considérer, dans votre base de donne, qu’un shot contient une instance d’asset place a tel endroit, il faut aussi avoir la liste des modifications de placement quelque part. Très souvent (enfin j’ai vu ça partout jusqu’à présent), la solution retenue face à ce dilemme est : « Si ce n’est pas juste un déplacement du contrôleur global, c’est de l’animation » et donc, c’est exporté avec l’alembic d’animation du plan (qui contient les personnages et les props déplacés). Mais avouez que c’est bête d’imposer l’export par plan d’un asset au complet quand seul un des objets qui le compose (un volet, une porte, etc.) est modifie… On a donc décidé de se lancer dans une quête un peu folle consistant à récupérer les modifications de placement des sous objets au layout pour pouvoir les appliquer sur l’asset original lors de la construction du plan au rendu. Pour être honnête, on eut pas vraiment le choix, le layout avait fait un gros travail de placement (il y a des contrôleurs, ils les bougent, c’est normal) quasiment plus aucun asset ne correspondait a sa position d’origine… Il fallait donc, pour les assets en questions, stocker la position des objets qui ne sont pas à leur placement d’origine. Sauf qu’il peut y avoir une différence entre le placement d’un contrôleur (que le layout déplace) et le placement de la géométrie qu’il contrôle. Le rig garantie (en principe, mais ce n’est pas le problème ici) que la relation de position entre un contrôleur et la géométrie qu’il contrôle est toujours la même. Mais il ne garantit pas que l’origine de la géométrie en question soit constante entre les versions de rig. Pas grave me diriez-vous, c’est pas le truc qui change souvent… Et devinez quoi ? Oui, c’est ce qui c’est passé, l’origine des géométries bougeait entre les versions de rig  . Rappelez-vous, le rig n’a été défini que très tard sur le projet et chaque choix se confrontait a ce qui était déjà en place. On ne pouvait donc pas s’appuyer sur la position des géométries mais uniquement sur celle des contrôleurs… Bon, on a les positions des contrôleurs modifiant un asset au plan, mais comment je connais la relation avec la géométrie ? C’est ici que les histoires sérieuses de sanity check on commencées. Il a fallu être extrêmement rigoureux sur la façon dont les contrôleurs « non-déformant » étaient connectées aux objets qu’ils contrôlaient. De sorte qu’il n’y eut qu’une simple matrice (intitulée sobrement offset matrice ou « matrice de décalage ») à appliquer sur la position en espace monde du contrôleur pour obtenir la position en espace monde de la géométrie (matrice du contrôleur + offset matrice = position identique dans Maya et Guerilla !). Il fallait donc stocker, par publication de rig, l’offset matrice de chaque contrôleur « non-déformant » puis l’utiliser lors de l’import d’un asset dans un plan. Mais attendez ! Attendez ! C’est même pas fini en plus lol ! Certains objets nécessitaient une hiérarchie de contrôleurs non-déformant et il fallait que mon bordel fonctionne avec eux aussi ! XD Il fallait donc stocker des numéros indiquant la profondeur du contrôleur pour appliquer les offset matrice dans le bon sens ! Le wagon était le premier assez du genre. La porte du wagon étant coulissante et compose d’un second objet (la serrure de la-dite porte). Je me rappelle de ma scène Guerilla que je passais mon temps a builder en tournant mon wagon et les contrôleurs de la porte et de la serrure dans tous les sens, a tous les niveaux de la hiérarchie en croisant les doigts pour obtenir le même résultât. J’ai du y passer une ou deux semaines à plein temps en mode chien méchant mais ça été super robuste car c’est une partie du code que je n’ai plus du tout touche par la suite.
. Rappelez-vous, le rig n’a été défini que très tard sur le projet et chaque choix se confrontait a ce qui était déjà en place. On ne pouvait donc pas s’appuyer sur la position des géométries mais uniquement sur celle des contrôleurs… Bon, on a les positions des contrôleurs modifiant un asset au plan, mais comment je connais la relation avec la géométrie ? C’est ici que les histoires sérieuses de sanity check on commencées. Il a fallu être extrêmement rigoureux sur la façon dont les contrôleurs « non-déformant » étaient connectées aux objets qu’ils contrôlaient. De sorte qu’il n’y eut qu’une simple matrice (intitulée sobrement offset matrice ou « matrice de décalage ») à appliquer sur la position en espace monde du contrôleur pour obtenir la position en espace monde de la géométrie (matrice du contrôleur + offset matrice = position identique dans Maya et Guerilla !). Il fallait donc stocker, par publication de rig, l’offset matrice de chaque contrôleur « non-déformant » puis l’utiliser lors de l’import d’un asset dans un plan. Mais attendez ! Attendez ! C’est même pas fini en plus lol ! Certains objets nécessitaient une hiérarchie de contrôleurs non-déformant et il fallait que mon bordel fonctionne avec eux aussi ! XD Il fallait donc stocker des numéros indiquant la profondeur du contrôleur pour appliquer les offset matrice dans le bon sens ! Le wagon était le premier assez du genre. La porte du wagon étant coulissante et compose d’un second objet (la serrure de la-dite porte). Je me rappelle de ma scène Guerilla que je passais mon temps a builder en tournant mon wagon et les contrôleurs de la porte et de la serrure dans tous les sens, a tous les niveaux de la hiérarchie en croisant les doigts pour obtenir le même résultât. J’ai du y passer une ou deux semaines à plein temps en mode chien méchant mais ça été super robuste car c’est une partie du code que je n’ai plus du tout touche par la suite.
 Cette séquence dans le wagon me fait toujours rire car Victor allume et éteint une lampe a huile en la touchant vaguement et certaines pommes sont posées sur des surfaces plates sans bouger alors que les plans subissent un shake cam pour simuler le mouvement des wagons .
Cette séquence dans le wagon me fait toujours rire car Victor allume et éteint une lampe a huile en la touchant vaguement et certaines pommes sont posées sur des surfaces plates sans bouger alors que les plans subissent un shake cam pour simuler le mouvement des wagons .
 Éclairer le contenu d’une boite fermée… Tout un programme. Si je me souviens bien les planches du fond et du dessus n’étaient pas visible des lights. Vous pouvez le remarquer sur les cheveux et le bras de Félicie. Les pommes étaient faites en particule. Je me rappelle avoir bossé sur un moyen de faire des variations de teinte sur le lookdev des pommes suivant un attribut de particule. Un effet subtil de variation de teinte.
Éclairer le contenu d’une boite fermée… Tout un programme. Si je me souviens bien les planches du fond et du dessus n’étaient pas visible des lights. Vous pouvez le remarquer sur les cheveux et le bras de Félicie. Les pommes étaient faites en particule. Je me rappelle avoir bossé sur un moyen de faire des variations de teinte sur le lookdev des pommes suivant un attribut de particule. Un effet subtil de variation de teinte.
 Un des money shot du film. Un money shot (qui peut se traduire de deux façons suivant qu’on l’achète ou suivant qu’on le budget ) est un plan qui est caractérisé par le cout nécessaire a sa fabrication et par l’effet Woaw ! qu’il est suppose engendrer chez le spectateur. Celui-ci part du pont d’Iéna, passe entre les fondations de la tour Eiffel puis fini sur une vue d’ensemble. C’était LE plan test du builder. Beaucoup de bâtiment, beaucoup de géométrie, beaucoup de personnages, beaucoup de spéculaire, beaucoup de textures, beaucoup de matte painting, etc. Paradoxalement, le fait de voir venir ces plans de loin (dès le layout tu te fais une idée de la difficulté) fait qu’au final il n’a pas pose de problèmes majeurs. Les problèmes vraiment contraignant arrivent souvent sur des plans totalement anodins.
Un des money shot du film. Un money shot (qui peut se traduire de deux façons suivant qu’on l’achète ou suivant qu’on le budget ) est un plan qui est caractérisé par le cout nécessaire a sa fabrication et par l’effet Woaw ! qu’il est suppose engendrer chez le spectateur. Celui-ci part du pont d’Iéna, passe entre les fondations de la tour Eiffel puis fini sur une vue d’ensemble. C’était LE plan test du builder. Beaucoup de bâtiment, beaucoup de géométrie, beaucoup de personnages, beaucoup de spéculaire, beaucoup de textures, beaucoup de matte painting, etc. Paradoxalement, le fait de voir venir ces plans de loin (dès le layout tu te fais une idée de la difficulté) fait qu’au final il n’a pas pose de problèmes majeurs. Les problèmes vraiment contraignant arrivent souvent sur des plans totalement anodins.
 Celui-là je ne mets pas parce qu’il est joli ( ) mais pour la petite histoire : Pour une raison qu’on ignore totalement, la texture des bouées (sur les bords du bateau) popait au rendu. On a jamais compris pourquoi et malgré tous nos tests (hashing des textures, hashing des uvs, compression, etc.) on a pas eu le temps de régler le souci suffisamment rapidement. Du-coup (et après discussion) elles ont été supprimées du bateau. Notez que ce n’est pas la règle. On ne supprime pas un truc à chaque fois qu’il nous embête, simplement qu’il faut constamment prioritiser les choses à faire, et parfois il faut trancher. Mais ce n’est jamais fait de gaité de cœur.
Celui-là je ne mets pas parce qu’il est joli ( ) mais pour la petite histoire : Pour une raison qu’on ignore totalement, la texture des bouées (sur les bords du bateau) popait au rendu. On a jamais compris pourquoi et malgré tous nos tests (hashing des textures, hashing des uvs, compression, etc.) on a pas eu le temps de régler le souci suffisamment rapidement. Du-coup (et après discussion) elles ont été supprimées du bateau. Notez que ce n’est pas la règle. On ne supprime pas un truc à chaque fois qu’il nous embête, simplement qu’il faut constamment prioritiser les choses à faire, et parfois il faut trancher. Mais ce n’est jamais fait de gaité de cœur.
 Ce plan (et la séquence d’une manière générale) fut le plan de test. On y est reste longtemps pour affiner nos méthodes d’exports d’alembic, de rendu sur la farm, déterminer quels AOVs on sort… Bref, pousser le pipeline pour faire, ce que j’appelle, la première boucle (un pipeline qui marche du début jusqu’au plan final composite). À l’époque il n’y avait pas de lighters ni de compositeurs, seul les superviseurs de ces deux départements étaient présents. C’est, je trouve, un des plans les plus travaille du film. La subtilité du rendu du sol ne se retrouve sur aucun plan. Il est aussi moins sature que le reste des plans.
Ce plan (et la séquence d’une manière générale) fut le plan de test. On y est reste longtemps pour affiner nos méthodes d’exports d’alembic, de rendu sur la farm, déterminer quels AOVs on sort… Bref, pousser le pipeline pour faire, ce que j’appelle, la première boucle (un pipeline qui marche du début jusqu’au plan final composite). À l’époque il n’y avait pas de lighters ni de compositeurs, seul les superviseurs de ces deux départements étaient présents. C’est, je trouve, un des plans les plus travaille du film. La subtilité du rendu du sol ne se retrouve sur aucun plan. Il est aussi moins sature que le reste des plans.
 Le plan qui suit. Notez la qualité du SSS de la peau, assez différente du reste du film.
Le plan qui suit. Notez la qualité du SSS de la peau, assez différente du reste du film.
 Juste pour préciser qu’il n’existe aucun axe dans Paris qui permet cette vue sur l’opéra.
Juste pour préciser qu’il n’existe aucun axe dans Paris qui permet cette vue sur l’opéra.
 Encore un plan de cette séquence que je trouve magnifique. C’est exactement comme Paris : Des pavés luisants avec un petit brouillard de fond. Ce cadrage est repris plusieurs fois dans le film mais le rendu n’a rien à voir.
Encore un plan de cette séquence que je trouve magnifique. C’est exactement comme Paris : Des pavés luisants avec un petit brouillard de fond. Ce cadrage est repris plusieurs fois dans le film mais le rendu n’a rien à voir.
 Les pavés sont 100 % displacement. On a essayé en normal map et tout mais vers la fin du plan, le sol apparaissait beaucoup trop plat.
Les pavés sont 100 % displacement. On a essayé en normal map et tout mais vers la fin du plan, le sol apparaissait beaucoup trop plat.
 Anecdote intéressante, le temps de rendu de l’AOV des pavés sur ce plan prenait énormement de temps car, étant en displacement ET de biais, les rayons de la caméra faisait des tests d’intersections sur beaucoup de triangles avant d’en toucher un. Ce n’est pas forcement une bonne tactique d’avoir de gros temps de rendu sur des plans comme ceux-là qui risquent de passer beaucoup de temps avant d’être valide.
Anecdote intéressante, le temps de rendu de l’AOV des pavés sur ce plan prenait énormement de temps car, étant en displacement ET de biais, les rayons de la caméra faisait des tests d’intersections sur beaucoup de triangles avant d’en toucher un. Ce n’est pas forcement une bonne tactique d’avoir de gros temps de rendu sur des plans comme ceux-là qui risquent de passer beaucoup de temps avant d’être valide.
 Ce décor a été fait sur plan. On avait énormément de livres au studio sur l’Opéra de Paris et même une petite maquette carton. Ce fut aussi un des candidats pour l’outil de récupération d’instance implicite car nombre d’objets se répètent. J’ajoute qu’il ne fut pas simple du tout à éclairer. Sur des plans rapprochés, on remplaçait les lights hors cadre chacun des lampadaires (4-5 par lampadaire, sans compter les bougies) par une seule light, plus grosse, mais a l’intensité et la couleur globale similaire. Cette méthode de « dégrossissement » du lighting permettait de diminuer le nombre de lights sur un plan (et donc diminuer le temps de rendu et le grain) sans modifier le retour visuel. Donc oui, gros travail sur ce décor.
Ce décor a été fait sur plan. On avait énormément de livres au studio sur l’Opéra de Paris et même une petite maquette carton. Ce fut aussi un des candidats pour l’outil de récupération d’instance implicite car nombre d’objets se répètent. J’ajoute qu’il ne fut pas simple du tout à éclairer. Sur des plans rapprochés, on remplaçait les lights hors cadre chacun des lampadaires (4-5 par lampadaire, sans compter les bougies) par une seule light, plus grosse, mais a l’intensité et la couleur globale similaire. Cette méthode de « dégrossissement » du lighting permettait de diminuer le nombre de lights sur un plan (et donc diminuer le temps de rendu et le grain) sans modifier le retour visuel. Donc oui, gros travail sur ce décor.

 Je vous présente mon personnage favori sur ce film : Odette. J’avais très peur que ses vêtements à base de laine ne passent pas ou mal à l’écran. Au final je trouve que ce sont les vêtements les mieux réussi du film. L’écharpe et le petit drape sur les épaules sont faits en displacement pour l’épaisseur de la laine. Ça fait toute la différence.
Je vous présente mon personnage favori sur ce film : Odette. J’avais très peur que ses vêtements à base de laine ne passent pas ou mal à l’écran. Au final je trouve que ce sont les vêtements les mieux réussi du film. L’écharpe et le petit drape sur les épaules sont faits en displacement pour l’épaisseur de la laine. Ça fait toute la différence.

 J’ai remarqué un truc sur les longs-métrages : L’attachement des différentes personnes travaillant sur le projet aux personnages du film est réel et souvent révélateur de la profondeur du film. Si sur un projet, aucun personnage ne semble intéresser les gens ou donner envie d’en savoir plus, c’est que quelque chose n’est pas bien passe. Je ne parle pas d’animation, mais de chara-design : Le faciès, l’attitude, la voix et l’histoire du personnage doivent questionner, donner envie que le personnage réussisse (ou perde dans le cas du méchant). C’est assez caractéristique dans les films « commerciaux » il faut réussir à développer suffisamment de personnage pour qu’une cible de spectateurs puisse s’identifier. À un rôle crucial la dedans. Merante avait aussi une histoire très développée.D
J’ai remarqué un truc sur les longs-métrages : L’attachement des différentes personnes travaillant sur le projet aux personnages du film est réel et souvent révélateur de la profondeur du film. Si sur un projet, aucun personnage ne semble intéresser les gens ou donner envie d’en savoir plus, c’est que quelque chose n’est pas bien passe. Je ne parle pas d’animation, mais de chara-design : Le faciès, l’attitude, la voix et l’histoire du personnage doivent questionner, donner envie que le personnage réussisse (ou perde dans le cas du méchant). C’est assez caractéristique dans les films « commerciaux » il faut réussir à développer suffisamment de personnage pour qu’une cible de spectateurs puisse s’identifier. À un rôle crucial la dedans. Merante avait aussi une histoire très développée.D

 Les plans de nuit sont rares dans les films d’animation. Pourtant, une grande partie de Ballerina se passe la nuit ce qui donne des effets super intéressants. L’éclairage du visage d’Odette par la lampe (blanche et froide vous aurez remarqué) de la grande méchante, ainsi que l’alternance classique bleu marin/orange cache une décision plus rationnelle : À l’origine, énormément de plans devait se dérouler dans les rues de Paris. Une des premières décisions fut de s’arranger pour que ces plans se passent de nuit de manière à diminuer le nombre de personnage secondaires. C’est encore plus tard que presque tous les plans de Paris disparurent au profit de plans dans la cour intérieure.
Les plans de nuit sont rares dans les films d’animation. Pourtant, une grande partie de Ballerina se passe la nuit ce qui donne des effets super intéressants. L’éclairage du visage d’Odette par la lampe (blanche et froide vous aurez remarqué) de la grande méchante, ainsi que l’alternance classique bleu marin/orange cache une décision plus rationnelle : À l’origine, énormément de plans devait se dérouler dans les rues de Paris. Une des premières décisions fut de s’arranger pour que ces plans se passent de nuit de manière à diminuer le nombre de personnage secondaires. C’est encore plus tard que presque tous les plans de Paris disparurent au profit de plans dans la cour intérieure.
 L'éclairage des escaliers se révèle toujours assez compliqué. En effet, il faut beaucoup de lumières éclairant différentes parties distinctes, mais le path tracer a souvent du mal à deviner quelle lumière éclaire quelle partie, ce qui amène facilement du grain.
L'éclairage des escaliers se révèle toujours assez compliqué. En effet, il faut beaucoup de lumières éclairant différentes parties distinctes, mais le path tracer a souvent du mal à deviner quelle lumière éclaire quelle partie, ce qui amène facilement du grain.
 Ce plan fut assez compliqué à faire en raison du nombre de miroir et d’AOV nécessaire a la recomposition de l’image. En effet, quand on a une réflexion pure (un miroir) il faut trouver un moyen de propager les AOV dans la réflexion pour pouvoir les sortir séparéments. Ensuite, il faut recompositer chacun des miroirs pour finalement les intégrer au plan. Bon, le problème vient du fait qu’il fallait aussi fournir une Z de qualité pour la version stéréo. Il fallait donc aussi propager la Z.
Ce plan fut assez compliqué à faire en raison du nombre de miroir et d’AOV nécessaire a la recomposition de l’image. En effet, quand on a une réflexion pure (un miroir) il faut trouver un moyen de propager les AOV dans la réflexion pour pouvoir les sortir séparéments. Ensuite, il faut recompositer chacun des miroirs pour finalement les intégrer au plan. Bon, le problème vient du fait qu’il fallait aussi fournir une Z de qualité pour la version stéréo. Il fallait donc aussi propager la Z.
 Ce plan fut mon plan de test pour les outils de projection en matte painting. J’avoue ne plus me rappeler du tout pourquoi la projection était nécessaire mais que j’étais trop fier quand mes petits calculs me rendaient une projection « pixel-perfect » du rendu dans Nuke !
Ce plan fut mon plan de test pour les outils de projection en matte painting. J’avoue ne plus me rappeler du tout pourquoi la projection était nécessaire mais que j’étais trop fier quand mes petits calculs me rendaient une projection « pixel-perfect » du rendu dans Nuke !
 Le directeur de l’Opéra fut le premier adulte en lookdev. Il a été utilisé pour par mal d’expérimentation concernant le rendu des visages et en particulier le nez qui devait avoir des bords bien définis. L’origine remonte a une décision de rig qui avait demande au modeling de diminuer la complexité des maillages des visages, cassant ainsi les bordures du nez. Je pense qu’on aurait pu faire différemment, mais je n’avais pas mon mot a dire. Bref, donc : À la charge du rendu d’afficher quelque chose de convaincant. On est naturellement parti sur des normales mais le problème du normal mapping basse fréquence c’est qu’il commence a devenir bizarre en gros plan quand l’axe de la caméra devient tangent à la surface (en faisant apparaitre une sorte de liseré sur la couche de réflexion). J’ai donc dû me pencher sur un peu de math pour proposer un moyen de switcher du normal map au displacement suivant les plans. Pour être honnête, je ne suis pas sûr que le displacement fut utilise sur beaucoup de plans.
Le directeur de l’Opéra fut le premier adulte en lookdev. Il a été utilisé pour par mal d’expérimentation concernant le rendu des visages et en particulier le nez qui devait avoir des bords bien définis. L’origine remonte a une décision de rig qui avait demande au modeling de diminuer la complexité des maillages des visages, cassant ainsi les bordures du nez. Je pense qu’on aurait pu faire différemment, mais je n’avais pas mon mot a dire. Bref, donc : À la charge du rendu d’afficher quelque chose de convaincant. On est naturellement parti sur des normales mais le problème du normal mapping basse fréquence c’est qu’il commence a devenir bizarre en gros plan quand l’axe de la caméra devient tangent à la surface (en faisant apparaitre une sorte de liseré sur la couche de réflexion). J’ai donc dû me pencher sur un peu de math pour proposer un moyen de switcher du normal map au displacement suivant les plans. Pour être honnête, je ne suis pas sûr que le displacement fut utilise sur beaucoup de plans.
 Il a eu un truc de vraiment problématique avec les intérieurs de l’Opéra de Paris et en particulier ce plan : Tout est plat et répétitif. Je me rappelle d’un couloir tellement basique que le DA était assis près du superviseur ligthing pendant plusieurs jours pour réussir a faire un truc « regardable ». Au final, la réalisation et l’animation des personnages prends le dessus et on y attache peu d’importance mais oui, éclairer des murs plats ce n’est pas la joie.
Il a eu un truc de vraiment problématique avec les intérieurs de l’Opéra de Paris et en particulier ce plan : Tout est plat et répétitif. Je me rappelle d’un couloir tellement basique que le DA était assis près du superviseur ligthing pendant plusieurs jours pour réussir a faire un truc « regardable ». Au final, la réalisation et l’animation des personnages prends le dessus et on y attache peu d’importance mais oui, éclairer des murs plats ce n’est pas la joie.

 Cette pièce est le premier « gros » intérieur qui a été préparé pour le rendu. Il apparait en effet sur beaucoup de plans du teaser. Lui aussi était dur à aborder car si on enlève les parquets, il y a peu de zones vraiment intéressantes en termes d’éclairage. Notez aussi que tout l’éclairage est diffus et il y a peu d’éclairage direct. Anecdote intéressante : Un grand miroir se situe au centre de la pièce mais posait pas mal de soucis autant techniques que narratifs. Au final, un grand drap a été mis dessus ni vue ni connue.
Cette pièce est le premier « gros » intérieur qui a été préparé pour le rendu. Il apparait en effet sur beaucoup de plans du teaser. Lui aussi était dur à aborder car si on enlève les parquets, il y a peu de zones vraiment intéressantes en termes d’éclairage. Notez aussi que tout l’éclairage est diffus et il y a peu d’éclairage direct. Anecdote intéressante : Un grand miroir se situe au centre de la pièce mais posait pas mal de soucis autant techniques que narratifs. Au final, un grand drap a été mis dessus ni vue ni connue.
 Ici, la manche de Victor est en gros plan. Le lighting a donc choisi d’appliquer du displacement pour ajouter du détail et de la nuance dans la forme. Mais comme le rig n’était pas recentrable, les vertices de la géométrie vibraient légèrement. En soi, ce n’est pas trop problématique quand les vertices sont éloignés les uns des autres. Mais quand on displace, il y a un vertice tous les deux/trois pixels, du-coups le flickering commence à se voir (sous la forme d’un léger « bourdonnement » de la manche). Comment régler ce souci comme un vrai pro ? On prend la scène d’anim, on décale le personnage d’une distance particulière en vu de le rapprocher du centre (2000 en x par exemple), on ré-exporte l’alembic, on met a jour l’alembic dans Guerilla, puis on décale le personnage de 2000 en x dans l’autre sens.
Ici, la manche de Victor est en gros plan. Le lighting a donc choisi d’appliquer du displacement pour ajouter du détail et de la nuance dans la forme. Mais comme le rig n’était pas recentrable, les vertices de la géométrie vibraient légèrement. En soi, ce n’est pas trop problématique quand les vertices sont éloignés les uns des autres. Mais quand on displace, il y a un vertice tous les deux/trois pixels, du-coups le flickering commence à se voir (sous la forme d’un léger « bourdonnement » de la manche). Comment régler ce souci comme un vrai pro ? On prend la scène d’anim, on décale le personnage d’une distance particulière en vu de le rapprocher du centre (2000 en x par exemple), on ré-exporte l’alembic, on met a jour l’alembic dans Guerilla, puis on décale le personnage de 2000 en x dans l’autre sens.
 Ce plan séquence fut surement le plus compliqué du film. Il a pris plus d’un mois a un graphiste senior à plein temps pour en venir a bout. Chaque personnage était présent deux a trois fois dans la scène et le layout les a faits s’alterner pour donner l’impression d’une continuation. L’éclairage était un cauchemar (extérieur, intérieur puis extérieur) du-coup beaucoup de choses ont été séparé ce qui est très risqué car cela entraine souvent de la mauvaise intégration et une difficulté à garder un éclairage cohérent (c’est souvent le cas sur les plans « sur-composités »). Et pourtant, j’avoue ne pas lui trouver de défauts. Franchement le boulot est impeccable de bout en bout.
Ce plan séquence fut surement le plus compliqué du film. Il a pris plus d’un mois a un graphiste senior à plein temps pour en venir a bout. Chaque personnage était présent deux a trois fois dans la scène et le layout les a faits s’alterner pour donner l’impression d’une continuation. L’éclairage était un cauchemar (extérieur, intérieur puis extérieur) du-coup beaucoup de choses ont été séparé ce qui est très risqué car cela entraine souvent de la mauvaise intégration et une difficulté à garder un éclairage cohérent (c’est souvent le cas sur les plans « sur-composités »). Et pourtant, j’avoue ne pas lui trouver de défauts. Franchement le boulot est impeccable de bout en bout.
 Regardez les variations de positionnement des volets. C’est à ça qu’a servi le travail que je vous exposais plus haut avec l’histoire de la porte du wagon. Vous allez me dire que tout le monde s’en fout mais tous les objets ont bénéficié d’un travail de cadrage (on parle souvent de « set-dressing ») de la part du layout et je pense vraiment que ça rend l’image plus naturelle.
Regardez les variations de positionnement des volets. C’est à ça qu’a servi le travail que je vous exposais plus haut avec l’histoire de la porte du wagon. Vous allez me dire que tout le monde s’en fout mais tous les objets ont bénéficié d’un travail de cadrage (on parle souvent de « set-dressing ») de la part du layout et je pense vraiment que ça rend l’image plus naturelle.


 Cette séquence fut une des première à être éclaire en utilisant le principe des shot groups, par un seul graphiste. L’ensemble est hyper homogène.
Cette séquence fut une des première à être éclaire en utilisant le principe des shot groups, par un seul graphiste. L’ensemble est hyper homogène.
 Hahaha ! Je me rappelle bien cette séquence : L’échelle du projet était de 1 unité = 10 cm. C’est peut-être peu commode mais ça résolvait pas mal de soucis. C’était un bon compromis. Le FX guy avait mal configuré son échelle de décimation. Du-coup, le premier export des volumétriques de ce plan était monstrueusement énorme, genre un triangle par pixel ! Mais le pire c’est qu’on avait mis en place un système qui appliquait une subdivision de 1 a tous les mesh
Hahaha ! Je me rappelle bien cette séquence : L’échelle du projet était de 1 unité = 10 cm. C’est peut-être peu commode mais ça résolvait pas mal de soucis. C’était un bon compromis. Le FX guy avait mal configuré son échelle de décimation. Du-coup, le premier export des volumétriques de ce plan était monstrueusement énorme, genre un triangle par pixel ! Mais le pire c’est qu’on avait mis en place un système qui appliquait une subdivision de 1 a tous les mesh  . Resultat.
. Resultat.
 Le toit de l’opéra était un des assets les plus massifs en termes de travail pour les textures. Les instances implicites ont eu un gros impact sur le quotidien des graphistes travaillant sur cet asset.
Le toit de l’opéra était un des assets les plus massifs en termes de travail pour les textures. Les instances implicites ont eu un gros impact sur le quotidien des graphistes travaillant sur cet asset.
 L’atelier fut le plan de test ultime pour la builder. Il y a des objets partout, dans toutes les positions. Si ça build correctement, tout le film devrait marcher (pas vrai ? ).
L’atelier fut le plan de test ultime pour la builder. Il y a des objets partout, dans toutes les positions. Si ça build correctement, tout le film devrait marcher (pas vrai ? ).
 Dans le bar breton, un des drapeau fait référence à l'endroit ou ce film a été fabriqué. Saurez-vous trouver lequel?
Dans le bar breton, un des drapeau fait référence à l'endroit ou ce film a été fabriqué. Saurez-vous trouver lequel?
 Un plan pour lequel je me serai beaucoup battu mais qui aura eu raison de moi. Je ne sais pas si vous avez déjà fais des soirées (nuits ?) à Paris mais la réflexion des éclairages publiques sur les paves (très sombres) est très présent, quand bien même il n’a pas plu. Sur ce plan la réflexion était trop plate, car la normal map semblait devenir neutre après quelques mètres, donnant un effet tout lisse. Malgré mes tentatives pour redonner un peu de consistance au sol, la réflexion a été très atténué pour pouvoir livrer à temps. Au final il passe très bien dans le film. J’ai juste un blocage personnel dessus.
Un plan pour lequel je me serai beaucoup battu mais qui aura eu raison de moi. Je ne sais pas si vous avez déjà fais des soirées (nuits ?) à Paris mais la réflexion des éclairages publiques sur les paves (très sombres) est très présent, quand bien même il n’a pas plu. Sur ce plan la réflexion était trop plate, car la normal map semblait devenir neutre après quelques mètres, donnant un effet tout lisse. Malgré mes tentatives pour redonner un peu de consistance au sol, la réflexion a été très atténué pour pouvoir livrer à temps. Au final il passe très bien dans le film. J’ai juste un blocage personnel dessus.
 OK, j’avoue, ce projet a développé en moi un fétichisme pour les vieux parquets bien lustrés…
OK, j’avoue, ce projet a développé en moi un fétichisme pour les vieux parquets bien lustrés… 
 Pour faire valider les diamants de la couronne de ce personnage, les lookdev a dû honteusement tricher en augmentant l’intensité de ces derniers aux points qu’ils créaient de la lumière. Path tracer oblige, on se retrouvait avec des points blancs sur les plans ou ce personnage apparaissait. On a mis un peu de temps à trouver, mais des petits points blancs dans un plan (appelés fireflies) sont souvent dû à un shader qui renvoi une haute valeur.
Pour faire valider les diamants de la couronne de ce personnage, les lookdev a dû honteusement tricher en augmentant l’intensité de ces derniers aux points qu’ils créaient de la lumière. Path tracer oblige, on se retrouvait avec des points blancs sur les plans ou ce personnage apparaissait. On a mis un peu de temps à trouver, mais des petits points blancs dans un plan (appelés fireflies) sont souvent dû à un shader qui renvoi une haute valeur.
 Comme bien souvent avec les « trucs à plume » la poule est un asset qui a demande beaucoup de travail, avec du Yeti et quelques morceaux de shader écris pour l’occasion. Un des running gag original du film consistait a la faire revenir plusieurs fois a l’écran tout au long du film.
Comme bien souvent avec les « trucs à plume » la poule est un asset qui a demande beaucoup de travail, avec du Yeti et quelques morceaux de shader écris pour l’occasion. Un des running gag original du film consistait a la faire revenir plusieurs fois a l’écran tout au long du film.
 Ce plan est très différent des autres en termes de colorimétrie. On est beaucoup plus sur des teintes Pixar/Illumination. Au passage, le personnage de la mère de Félicie fut la favorite d’une partie de l’équipe pendant longtemps mais le fait qu’elle apparaisse qu’une seule fois (sur un plan fait vers la fin de la production), n’a, je pense, pas permis aux différentes personnes intervenants dessus d’y passer le temps nécessaire.
Ce plan est très différent des autres en termes de colorimétrie. On est beaucoup plus sur des teintes Pixar/Illumination. Au passage, le personnage de la mère de Félicie fut la favorite d’une partie de l’équipe pendant longtemps mais le fait qu’elle apparaisse qu’une seule fois (sur un plan fait vers la fin de la production), n’a, je pense, pas permis aux différentes personnes intervenants dessus d’y passer le temps nécessaire.
 Tu passes une prod à régler les soucis de hairs des personnages, les uns après les autres. Au bout d’un moment tout marche, tu penses que les problèmes de hair c’est fini, tu as déjà fêté ça il y a deux mois et BAM ! Tu as un nouveau plan qui tombe un peu avant la fin du projet. Avec au programme, un nouveau perso, visible uniquement sur ce plan, en gros plan avec les cils et les sourcils qui flickent !
Tu passes une prod à régler les soucis de hairs des personnages, les uns après les autres. Au bout d’un moment tout marche, tu penses que les problèmes de hair c’est fini, tu as déjà fêté ça il y a deux mois et BAM ! Tu as un nouveau plan qui tombe un peu avant la fin du projet. Avec au programme, un nouveau perso, visible uniquement sur ce plan, en gros plan avec les cils et les sourcils qui flickent !

 Je vais finir ce commentaire avec deux plans et un petit mot concernant l’animation. On l’entend souvent, l’animation est le truc le plus important et c’est vrai : Si les personnages ne sont pas « vivants », c’est terminé. Le lighting et le compo n’y pourront pas grand-chose. Le chara-design de Ballerina c’est pas le plus simple à aborder. Pour une raison qui m’échappe (je ne m’occupais pas du département anim), je trouve l’animation sur le projet inégale, mais il faut avouer que certains plans sont de belles réussites. Le plan du dessus est le tout dernier d’une séquence qui monte en puissance ou Félicie, malgré n’avoir plus aucune chance de devenir ballerine enfile ses chaussons, commence quelques pas puis fait des gestes de plus en plus complexe pour finir sur une pirouette plein plan le regard vers le dos de la caméra (Paris) avec deux sentiments en même temps sur son visage. Un sentiment clair, c’est bien pour du cartoon. Mais ce qui rend un personnage en 3d humain c’est en grande partie la manière dont il exprime (ou tente de cacher) l’ambivalence de ses sentiments. Ce sont des attitudes qu’on retrouve fréquemment dans le film. Disney excellait dans sa capacité à le faire en 2d et peu de films y arrivent vraiment. Je trouve que Ballerina s’en sort très bien là-dedans.
Je vais finir ce commentaire avec deux plans et un petit mot concernant l’animation. On l’entend souvent, l’animation est le truc le plus important et c’est vrai : Si les personnages ne sont pas « vivants », c’est terminé. Le lighting et le compo n’y pourront pas grand-chose. Le chara-design de Ballerina c’est pas le plus simple à aborder. Pour une raison qui m’échappe (je ne m’occupais pas du département anim), je trouve l’animation sur le projet inégale, mais il faut avouer que certains plans sont de belles réussites. Le plan du dessus est le tout dernier d’une séquence qui monte en puissance ou Félicie, malgré n’avoir plus aucune chance de devenir ballerine enfile ses chaussons, commence quelques pas puis fait des gestes de plus en plus complexe pour finir sur une pirouette plein plan le regard vers le dos de la caméra (Paris) avec deux sentiments en même temps sur son visage. Un sentiment clair, c’est bien pour du cartoon. Mais ce qui rend un personnage en 3d humain c’est en grande partie la manière dont il exprime (ou tente de cacher) l’ambivalence de ses sentiments. Ce sont des attitudes qu’on retrouve fréquemment dans le film. Disney excellait dans sa capacité à le faire en 2d et peu de films y arrivent vraiment. Je trouve que Ballerina s’en sort très bien là-dedans.
Il est bien évident que tout ceci est un effort collectif, nous n’étions jamais seuls à faire des choix et c’est sûrement ce qui a permis au projet d’aboutir. Je n’ai pas nommé les personnes, mais il me semble important de rappeler que c’est pourtant avec de l’humain que tout se joue, du haut de la hiérarchie jusqu’au graphiste parfois derrière des tableaux à vérifier que l’intégralité des retakes des plans ont été faites (et pour qui je peux vous garantir que ce n’est pas la tasse de café). Si personne ne le veut, le film ne sort pas, c’est aussi simple que ça.
Je ne parle pas d’aller se tailler les veines à faire des heures supplémentaires pendants des mois pour le plaisir de montrer qu’on souffre à la tache mais au contraire d’une volonté farouche que tout ce passe pour le mieux à tous les niveaux et sur la longueur. Je n’ai dû faire qu’une vingtaine d’heure supplémentaires (pour finir et peaufiner le builder si ne me souvient bien car « Pas d’builder : Pas d’projet… »). Le fait de voir qu’il y a une volonté générale de réussite du projet et de bienveillance mutuel (OK je m’enflamme peut-être un peu sur le dernier mais quand même c’est l’idée) pousse les gens à fournir l’effort supplémentaire nécessaire à la sortie d’images propre et livrées dans les temps. La peur de se faire virer n’est pas déterminante, chacun sait qu’une fois le projet fini on passe (presque tous) à la porte. À partir de là, ce qui compte pour chacun c’est de faire un travail dont il est fier. À quoi bon livrer des images, sensé divertir les gens qui les regarde, faites dans la tension et dont tous le monde garde un gout amer ? À mes yeux, et malgré un double démarrage difficile, Ballerina semble également avoir réussi sur ce terrain et pour un premier long-métrage, c’est la classe !
A bientôt !
Dorian
 Si vous assignez un shader (de volume par exemple) il peut être utile de pouvoir le désassigner, plus loin dans le rendergraph.
Si vous assignez un shader (de volume par exemple) il peut être utile de pouvoir le désassigner, plus loin dans le rendergraph.
Il me semble que c’était possible en 1.3 mais que ce ne soit plus possible en 1.4.
Je vous propose donc une petite méthode pour désassigner un shader.
Mais expliquons un peu le souci. 
Faites une petite scène « sphère et plan » puis faite un override d’assignation de shader mais videz le nom du shader :

Puis connectez l’override à la branche principale. Comme vous pouvez le constater, l’assignation reste faite en bout de graph :

Bon sang, quand j’override par « rien du tout » Guerilla garde la valeur de l’override original. 
Et Guerilla semble sciemment considérer que vous avez fais une erreur :
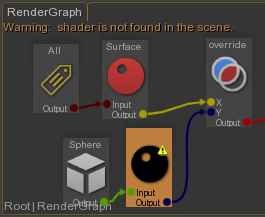
On va résoudre ça. Supprimez l’assignation puis créez un nœud de Script (Ctrl+Espace, « scri », Entrée):

Connectez le dans le graph à la place de votre assignation précédente :
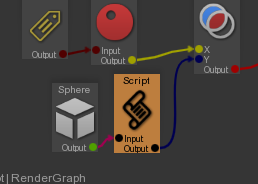
Regardez ses attributs. Le script arrive avec un petit exemple pour illustrer son comportement. Mais nous n’allons pas en avoir besoin. Supprimez les deux propriétés (en cliquant sur les croix en haut à droite), puis cliques sur le bouton « Edit »:

Sans vous soucier des commentaires regardez ce que vous avez :
if Input then
Output = duplicate (Input)
Output["variable."..ColorName] = CustomShaderColor
end
Je vous explique rapidement : Ce script duplique la table (c’est la structure de données en lua) Input en Output, modifie l’entrée « variable.DiffuseColor » (car il récupère la valeur de l’attribut « ColorName » que nous avons supprimé précédemment) pour lui mettre la valeur de l’attribut « CustomShaderColor » que nous avons, lui aussi, supprimé (c’était la couleur rouge).
On va utiliser ce mécanisme pour venir supprimer l’assignation du shader. Mais reste la question : Quel est le nom de l’attribut à modifier ?
Pour cela rien de plus simple : Ouvrez la console (menu « View|Show/Hide console (Alt+2) »), sélectionnez votre sphère puis faites Shift+D. Ceci va afficher, dans la console, la liste de tous les attributs ainsi que leur valeur telles qu’elles seraient envoyées au rendu. Cherchez « shader »:
shade.shadebothsides: 0
shade.textureapproximation: "glossy"
shade.texturemaxsize: 0
shader.displacement: ""
shader.surface: "Surface"
shader.volume: ""
shape.cached: 1
shape.combineprocedural: 0
shape.compression: 0
Vous l’avez ! « shader.surface » (ou « shader.volume » ou même « shader.displacement » si vous souhaitez supprimer le shader de displacement).
Modifiez le script pour supprimer l’assignation :
if Input then
Output = duplicate (Input)
Output["shader.surface"] = ""
end
Sauvez Ctrl+S puis vérifiez par vous même :
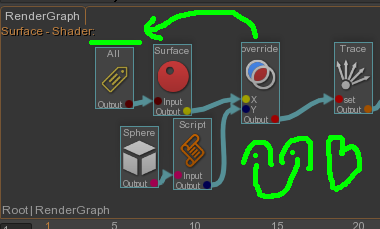
Comme vous pouvez le voir, le shader est désassigné.
En espérant que ça en débloque certains.
À bientôt !
Dorian
{kind=link}