Mise à jour
Mise à jour de la base de données, veuillez patienter...
source: blog.fevrierdorian.com
Si vous faites des playblasts déportés, il y a de fortes chances que vous mettiez une machine dédiée qui ouvre une session graphique de Maya, ouvre (par exemple) votre scène d'animation, puis lance le playblast. Cela faisant, il est possible que les premières images de votre playblast n'ai pas tous les matériaux et textures (surface vertes), ce qui est assez gênant. 
Dans ce billet, je vous propose d'essayer de comprendre le problème et de regarder comment le résoudre. 
Depuis un petit moment, les développeurs de Maya tentent d’isoler l’interface graphique afin que cette dernière ne se bloque jamais. Ainsi, le chargement des textures et la préparation des matériaux du viewport se fait en arrière-plan. Maya est ensuite informé qu’il peut utiliser les ressources immédiatement, car ces dernières sont chargées. Il y a alors un blocage de quelques millisecondes et les textures et matériaux apparaissent.
Ce procédé augmente la durée totale du chargement (x 1,1 d’après la documentation), mais le fait que ce chargement soit fait en arrière-plan, sans bloquer l’utilisateur, en diminue fortement la perception.
Le mode « Parallel » utilise un thread séparé, dédié à la construction des matériaux et aux demandes de chargement des textures, vous permettant de continuer à travailler sur la scène pendant que les matériaux se construisent et que les textures se chargent. Le temps de chargement total est généralement 1,1 fois supérieur à celui du mode « Immediate ».
(traduction de la documentation)
Le problème, pour nos playblast, vient du fait que Maya n’attende pas que tout soit chargé avant de le démarrer, ce dernier calculant une, voir plusieurs, images possiblement incomplètes. Bien entendu, le problème n’apparaît pas lors d’une utilisation manuelle de Maya car les matériaux et textures ont le temps de se charger. 
C’est peut-être un bug. J’ai, en effet, tendance à croire que le but de la commande playblast est de faire un… playblast et donc, que Maya devrait attendre avant de démarrer. Dans tous les cas, ce n’est pas ce qu’il fait, nous laissant avec des animateurs, réalisateur et superviseurs mécontents (pléonasme ?  ).
).
Vous vous en doutez, il faut qu’on passe le chargement des matériaux et des textures en « Immediate », ce qui aura pour effet de bloquer Maya jusqu’à ce que tout ce qui est nécessaire à l’image soit chargé. 
Il y a deux façons de faire ça. 
Vous pouvez résoudre le problème localement en passant par les préférences de l’utilisateur : Display > Heads Up Display > Material Loading Details. (voir la page de documentation précédente).
Comme vous vous en doutez, cette solution est loin d’être optimale : Si vous gérez une ferme de calcul, il peut être contraignant d’avoir à modifier les préférences sur chaque machine.
Cette commande permet de manipuler les paramètres globaux d’affichage. Depuis Maya 2016 (J’ai vérifié…), les développeurs ont ajouté un argument dédié : materialLoadingMode.
Cet argument, peut prendre trois valeurs (fichtre, je suis sûr qu’il vous tarde de savoir lesquels) :
Qu’est-ce que vous faites encore là ? Vos animateurs souffrent, leurs playblasts ont besoin de vous !
Merci à Paul-Émile pour le tuyau. 

Aujourd'hui je vais vous parler d'une commande que vous devez connaître si vous avez à gérer un pipeline Maya qui tourne sous Windows, Linux et autres.
Imaginons que les scènes des départements de votre studio soient sous Windows.
Si votre lecteur réseau est P:/ (fichtre, que c’est original), les chemins auront la forme :
P:/usbolossmurica/layout/layout_v142.mb
P:/usbolossmurica/anim/anim_v032_realalacon.mb
P:/usbolossmurica/rendu/rendu_v142_valid_retake_josef_pala_aujourdui (copy 1).mb
Des fichiers de prod quoi ! 
Comme vous êtes un vrai bonhomme·e, vous êtes sous Linux, mais il arrive, malheureusement, que vous ayez à lever la tête de votre code, parfait et sublime est-il nécessaire de le préciser, dont vous avez la bonté de faire bénéficier celui qui vous emploi, pour mettre votre nez dans cette matière fécale si particulière à notre industrie que sont les scènes de production.
Cela faisant vous devez, n’ayons pas peur des mots, ouvrir des scènes de graphistes.
Aussi surprenant que cela puisse paraître, Maya est un logiciel fait par des gens comme vous moi, des gens humbles, des petits cœurs qui souffrent quand ils doivent ouvrir des scènes venant de Windows.
Alors je sais, certains aiment Windows, je ne juge pas ; après tout, il m’arrive aussi d’aller au McDonald (En revanche, il tombe sous le sens que les pines-d’huîtres sous Mac peuvent crever).
Fin de l’aparté. 
Je disais donc : Maya propose une commande sur mesure ; dirmap.
Le principe est de rediriger les répertoires de votre scène Maya vers d’autres répertoires.
Si votre point de montage de production sous Linux est /prod/, faites ceci avant d’ouvrir vos scènes :
import maya.cmds as mc
mc.dirmap(enable=True)
mc.dirmap(mapDirectory=("P:/", "/prod/"))
Comme vous le devinez, ceci va transformer P:/ par /prod/ dans tous les chemins trouvés par Maya. C’est comme un seurchaindriplèsse automatique. 
Par défaut, dirmap n’est pas activé, c’est la raison de la présence de l’appel :
mc.dirmap(enable=True)
Cette activation n’est pas conservée entre les sessions. Il faut donc l’activer et le configurer à chaque fois que vous en aurez besoin (e.g. En passant par userSetup.[mel/py]).
Dès lors, vous pouvez ouvrir un fichier avec des références (scène, texture…) au format Windows et vous remarquerez que tout fonctionne de façon transparente. 
Vous pouvez listez les mappings actuels en utilisant l’argument getAllMappings :
mc.dirmap(getAllMappings=True)
# Result: [u'P:', u'/prod'] #
Si vos scripts ont besoin de manipuler des chemins en prenant en compte le dirmap vous pouvez utiliser l’argument convertDirectory :
mc.dirmap(convertDirectory="P:/machin/bidule")
# Result: /prod/machin/bidule #
Vous pouvez obtenir le mapping défini depuis son « point d’entrée » grâce à getMappedDirectory :
mc.dirmap(getMappedDirectory="P:")
# Result: /prod #
Notez que je n’ai pas mis le "/" à la fin. J’ai utilisé la valeur retournée par l’argument getAllMappings expliqué plus haut.
Pour supprimer un mapping, on utilise l’argument unmapDirectory :
mc.dirmap(unmapDirectory="P:")
Arrive ici, vous ne devriez plus avoir de point de montage. 
Vous pouvez aussi monter plusieurs points (e.g. Un pour les Alembic, un pour les textures, un pour…) :
mc.dirmap(mapDirectory=("P:/toto/texture", "/un/point/de/montage"))
mc.dirmap(mapDirectory=("P:/toto/abc", "/autre/point/de/montage"))
Ce qui nous donne :
mc.dirmap(convertDirectory="P:/toto/texture/foo/bar.tex")
# Result: /un/point/de/montage/foo/bar.tex #
mc.dirmap(convertDirectory="P:/toto/abc/anim/foo.abc")
# Result: /autre/point/de/montage/anim/foo.abc #
Très pratique pour monter une ferme de calcul ou travailler avec un autre studio. 
Je pense que vous avez compris le principe. 
J’espère que cette astuce vous aura redonné le goût de vivre. Je vous invite à retirer cette corde, descendre de votre chaise, composer le 09 72 39 40 50 puis commencez à utiliser cette commande (Si vous êtes descendu avant de retirer la corde, composez directement le 15).

L’exécution de tâches (jobs) sur des gestionnaires de tâche (job manger, render manager, farm manager) sont courant dans énormément de secteurs liés à l’informatique. Que ce soit la compilation de code, l’exécution et le rapport de tests unitaires, le calcul financier, ça pullule. 
Internet regorge d’informations et de bonnes pratiques liées à l’exécution et la gestion de tâches sur des fermes de calcul. Pourtant, beaucoup de ses informations sont trop génériques et passe à côté de certains problèmes de fond, propre à notre industrie. 
Je voudrais, modestement et de façon totalement subjective, faire un retour d’expérience autour de l’organisation et la structure du code de ferme de calcul. Notez que je n’affirme pas avoir LA bonne méthode pour gérer les fermes de la façon la plus efficace qui soit, mais j’aborde et commente différentes problématiques que j’ai pu rencontrer.
Je vais passer en revu et commenter différentes choses. Je tenterais, dans les parties suivantes, d’établir quelques règles et guides à suivre puis je finirais sur une explication de l’organisation du code.
Avant de commencer je dois expliciter certains termes que je vais employer.
C’est le cerveau. Il s’agit du « serveur » :
Le job manager embarque souvent une base de donnée (PostgreSQL, MySQL, etc.) et ne doit jamais être indisponible pour les workers. 
« Travailleur » en français. Il s’agit d’un petit programme qui tourne et communique avec le job manager pour recevoir et exécuter des jobs. On exécute souvent un worker par machine de calcul, mais il n’est pas rare d’exécuter plusieurs workers sur une seule machine. Parfois pour des raisons de licences liées à la machine (une machine Yeti, plusieurs exports de .fur), parfois pour des raisons d’équilibre de charge. Ainsi, plusieurs petits jobs qui demandent peu de ressources peuvent n’exécuter en parallèle sur une seule machine. Notez qu’un gestionnaire de ferme évolué permet de gérer intelligemment les ressources d’une machine et de lancer plus ou moins de jobs suivant les exigences du job (licence, mémoire, etc.).
Bien que le terme français « tâche » existe, il fait souvent spécifiquement référence, en production, à la tâche du graphiste (traduction de « task », qu’on peut retrouver dans Shotgun). J’utilise donc le terme de « job » pour faire référence à ce que doit exécuter un worker.
Parfois appelé job requirement. C’est un concept qui est présent sous différentes formes dans la plupart des job managers du marché. Le principe est que chaque job contient des informations sur ce qui est nécessaire à son exécution. Plus ces informations sont complètes, plus le job manager pourra gérer au mieux la farm. Le cas le plus courant est le type et le nombre de licences nécessaire à l’exécution du job.
Voici un exemple d’exigence de job :
{'requirement': {'license': {'nuke': 1},
{'sapphire': 1}
'cpu_count': '12+',
'memory_min’: '8GB',
'memory_max': '64GB'}
Le dictionnaire suivant spécifie que le job :
L’aspect intéressant c’est que certaines informations peuvent aider le job manager à mieux organiser la soumission des jobs. Ainsi, en spécifiant memory_max, vous « garantissez » au job manger que le job ne fera jamais plus de 64 GB. Si, par exemple, vous avez des petits jobs qui n’utilise qu’un seul CPU vous pourriez spécifier cpu_count à 1 et le job manager saurait que votre job ne va utiliser qu’un seul CPU.
C’est une sorte de « contrat » que vous passez avec le job manager. C’est donc à double tranchant. Si vous lui dite que votre job utilisera 16 GB et qu’il monte à 64 GB, le worker aura des soucis pour l’exécuter.  Bien entendu, c’est celui qui génère le job à soumettre qui explicite ses exigences. Comme ce sont souvent les TD qui codent les chaînes de job, les exigences sont dans le code.
Bien entendu, c’est celui qui génère le job à soumettre qui explicite ses exigences. Comme ce sont souvent les TD qui codent les chaînes de job, les exigences sont dans le code. 
Le job de rendu est le type de job le plus courant. C’est souvent celui pour lequel vous souhaitez mettre une ferme de rendu en place. 
Scène de travail -> images rendues .mb/.gproject | .exr
Comme ce sont souvent les jobs les plus longs, il est préférable de séparer la génération des fichiers de rendu (.rib, .ass, etc.) et le rendu de ces derniers en deux jobs distincts :
Scène de travail -> fichiers de rendu -> images rendues .mb/.gproject | .rib/.ass | .exr
La génération des fichiers de rendu consiste à ouvrir une scène (Maya/Guerilla/Katana/Poalobra) et à faire les exports des fichiers de rendu (.rib, .ass, etc.), sur un range d’image donné.
Dans le cas de Guerilla, on ouvre le .gprojet, on exporte un range d’image (paquet de 10 par exemple : 101-110, 111-120, etc.) en .rib.
Pourquoi ne pas exporter toutes les images plutôt que par petits paquets ? Tout simplement parce que le but est de garder la durée de vos jobs aussi consistante et contrôlable que possible.  Si on exportait « toutes les images », on aurait des temps très aléatoires suivant les plans du fait de la disparité de leur nombre d’images (certains plans font une trentaine d’image, d’autre plusieurs centaines). Si vous avez un bug sur la dernière image sur votre plan de 900 frames (oui parce qu’on a toujours un problème sur la PUTAIN de dernière image du plan le plus long du projet !
Si on exportait « toutes les images », on aurait des temps très aléatoires suivant les plans du fait de la disparité de leur nombre d’images (certains plans font une trentaine d’image, d’autre plusieurs centaines). Si vous avez un bug sur la dernière image sur votre plan de 900 frames (oui parce qu’on a toujours un problème sur la PUTAIN de dernière image du plan le plus long du projet !  ), il vous faudrait tout relancer. Et si l’export dure 30 minutes, vous allez passer des heures à le déboguer.
), il vous faudrait tout relancer. Et si l’export dure 30 minutes, vous allez passer des heures à le déboguer.
Diviser en paquet permet de rendre le temps humainement gérable.
Dans un monde idéal et instantané, on n’exportera qu’une seule image. Ceci permettrait d’avoir le job de rendu en dépendance directe sur le job de génération de fichier de rendu. Mais ce n’est pas possible, il y a un temps minimum nécessaire à l’ouverture de l’application et de la scène.
La taille des paquets dépendent de la lenteur générale de l’ouverture de la scène (Les scènes Maya peuvent être lente si elles ne sont pas « vides »). Plus la scène est lente à ouvrir, plus il est intéressant d’augmenter la taille du paquet.
J’utilise, en général, des paquets de 10 images pour Guerilla et 20 pour Maya. Mais c’est vraiment suivant la taille du projet.
Notez qu’il n’est pas toujours possible et/ou faisable d’avoir des jobs de génération de fichiers de rendu sur votre ferme de calcul. Par exemple, on peut vouloir rendre des ranges d’images directement depuis son logiciel favori (Maya à une époque et je suppose Blender, Cinema 4D, etc.). Cette méthode, plus « direct » peut se révéler chaotique dès lors que des problèmes apparaissent. Il faut être vigilant. 
C’est sûrement le type de job le plus long de la ferme de calcul. Je conseille fortement de n’avoir qu’une image par job.
Les informations importantes de tels jobs se situent dans le log. Certains job manager permettent de parser le log à la volée pour remonter des informations de façon claire (temps de rendu, fichiers manquants, etc.) voir, arrêter le job, faisant ainsi gagner un temps précieux.
Si les temps de rendu sont importants (12 heures et plus) et si votre moteur de rendu le permet, il peut être intéressant d’avoir accès à l’image « en l’état » avant la fin du rendu (au bout de 10 minutes par exemples) ceci permet de pouvoir s’assurer qu’aucun truc grossier n’est présent/absent du rendu et d’éviter de perdre des heures inutiles. 
La technique du pauvre consisterait à lancer deux jobs de rendu utilisant les mêmes fichiers de rendu mais avec des arguments de la ligne de commande différent :
Mais cela reste très imparfait, car quand le « vrai » rendu peut rarement partir dans les mêmes conditions que le premier. Il peut ainsi se retrouver sur une autre machine. Le meilleur reste donc d’utiliser l’image du rendu en cours. Si le moteur ne le permet pas, vous pouvez lancer une seule frame, au milieu du plan (ou une frame toutes les 5 frame par exemple) avec une priorité plus élevée. Vous n’attendez ainsi pas la fin complète des images pour en vérifier quelques-unes. Mais cette technique aussi est imparfaite, car vous ne voyez pas l’ensemble du plan, juste quelques images.
Dans les deux cas, cela vous permet de générer des vidéos de « pré-rendu », mais forcement, avec tout cela, le suivi du rendu est alourdi. 
 C’est sûrement le second job le plus courant : L’ouverture de scène puis l’export de son contenu au format Alembic.
C’est sûrement le second job le plus courant : L’ouverture de scène puis l’export de son contenu au format Alembic.
La méthode bourrine consiste à ouvrir la scène et tout exporter dans un gros fichier .abc.
Ouverture de la scène Maya -> Export Alembic
.mb | .abc
C’est lourd et complètement con. 
En pratique, il est plus pertinent de séparer les exports suivant leur nature. Ainsi, s’il y a 3 personnages dans la scène, l’animation de chaque personnage est exporté dans son Alembic respectif. Il est ainsi plus rapide de réexporter l’animation d’un seul personnage lors d’une retake.
Le plus intéressant étant encore de savoir ce que contient le plan à l’avance en vu de générer un job par personnage.
À l’instar du rendu, plutôt que de passer directement par un job d’export Alembic, on pourrait passer par une étape intermédiaire consistant à exporter l’ATOM des contrôleurs d’animation, puis un second job, celui exportant l’Alembic, partirait d’une scène vide, amènerait une version du rig (la dernière par exemple) appliquerait l’ATOM sur les contrôleurs d’animation puis ferait l’export.
Rig
|
v
Scène de travail -> fichiers ATOM -> Maya -> Export anim
.mb | .atom | | .abc
Mais on pourrait aller encore plus loin ! 
Pourquoi ne pas en profiter pour faire un preroll automatique pour nos amis du cloth et du FX ?
Pensez à garder les paramètres de numéro de frame modifiable afin que les départements puisse régénérer leur Alembic avec preroll si la version automatique n’est pas optimale.
Ce job s’occupe de générer des vidéos, souvent .mp4 depuis une séquence d’image (.jpeg, .exr, etc.). Ce dernier est loin d’être simple.
On peut utiliser Nuke pour bénéficier de tous les outils dont il dispose (texte, option d’export, etc.), mais Nuke n’est pas donné et nécessite une licence. 
Le module Python Pillow est vraiment très bon. Je le recommande chaudement. 
Pour les cartouches (bandes noir en haut et en bas, affichant des informations) je déconseille de calculer dynamiquement leur taille via un pourcentage. Gardez une taille fixe et connu et simple à retenir pour tout le monde (100 pixels, 150 pixels, 200 pixels, etc.).
+--------------------------------+ |text1 text4 text7 | |text2 text5 text8 | |text3 text6 text9 | |--------------------------------| | | | | | *picture* | | | | | |--------------------------------| |text10 text13 text16| |text11 text14 text17| |text12 text15 text18| +--------------------------------+
Neuf infos en haut et neuf infos en bas, soit 18 petits textes d’informations !
Liste non exhaustive d’informations intéressantes à mettre dans les cartouches :
Vous pouvez également ajouter une ou plusieurs images en début de vidéo avec plus d’informations (commentaire du graphiste, date des fichiers utilisés, mire colorimétrique, etc.).
Que l’on travaille dans un studio multi-site ou qu’on utilise les ferme de rendu dans le cloud, les jobs de synchro sont monnaies courante. Ces jobs ne prennent quasiment aucune ressource et ne font bien souvent rien d’autre qu’attendre. En effet, ils sont rarement chargés de faire la synchro eux-mêmes mais passe par un service dédié auquel ils envoient des informations des fichiers à synchroniser. Ensuite, ils attendent que le service de synchro leur dise que les fichiers demandés ont été synchronise. D’où l’importance de s’assurer qu’aucun worker dédié à une tâche lourde (rendu, export, etc.) n’exécute un job de synchro. Ce serait une perte de temps énorme. Pour cela il peut être pratique d’avoir une machine compose de dizaines de worker qui ne font qu’exécuter des jobs de synchro (c’est-à-dire attendre… ).
Une fois ces jobs exécutés ils « débloquent » les jobs en dépendance qui peuvent s’exécuter sur leur worker avec la garantie que les fichiers nécessaires sont présents.
Job de nettoyage
Souvent appelé cleanup jobs, leur mécanisme est parfois pris en charge par le job manager qui ne s’exécute qu’au moment de la suppression des jobs. On ne peut donc pas directement parler de « job » mais plutôt de cleanup list (le job contient la liste des fichiers/dossier à supprimer) :
{'cleanup':['/path/to/file.rib',
'/path/to/folder']}
Mais tous ne le gèrent pas comme ça et un job dédié reste la méthode traditionnelle.
Ce job sert tout simplement à supprimer les fichiers qui ne sont plus nécessaires. Ça peut être les .rib ou des .vrmesh généré à la volée par la chaîne de job mais qui ne servaient qu’au calcul d’une image.
Il fut un temps, ces jobs supprimaient les shadow map, les point-clouds, les brick maps, etc. qui pesaient très lourd.
C’est la fin de cette première partie ! J’espère que ça vous aura intéressé. La suite, un jour…
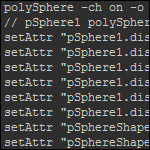 Il n’est pas rare, quand on script, de devoir récupérer le nom d’un attribut en vu de l’utiliser, plus tard, dans ses scripts. D’une manière générale, il suffit de modifier l’attribut, d’aller dans le Script Editor puis de trouver la ligne qui fait le setAttr sur l’attribut qui nous intéresse.
Il n’est pas rare, quand on script, de devoir récupérer le nom d’un attribut en vu de l’utiliser, plus tard, dans ses scripts. D’une manière générale, il suffit de modifier l’attribut, d’aller dans le Script Editor puis de trouver la ligne qui fait le setAttr sur l’attribut qui nous intéresse.
Vous remarquerez toutefois que cette méthode ne fonctionne pas avec certains attributs. Il arrive, en effet, que la commande setAttr correspondante ne soit pas affichée dans le Script Editor. Je vous propose ici la méthode que j’utilise pour aller trouver les attributs « timides ».
Avant de commencer, sachez qu’on ne peut pas parler de méthode à proprement parler tant il s’agit plutôt d’un bricolage. 
Première chose, trouvons un attribut qui n’affiche pas de commande setAttr dans le Script Editor. C’est le cas de l’attribut Smooth Mesh Preview des nœuds de type mesh.

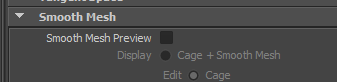
Essayez de le modifier, rien ne s’affiche. Vous pouvez activer Echo All Commands, l’attribut apparait une seule fois sur les 257 lignes qui s’affichent. Difficile de le trouver. 
Ce n’est donc pas la bonne méthode. Voici la mienne :
Le principe consiste à sauver deux fois la scène, une fois avec l’attribut dans un état, et l’autre fois avec l’attribut dans un autre état et de faire une différence ligne a ligne via un logiciel spécialisé. Allons-y ! 
Laissez l’attribut non modifié puis sauvez la scène en ASCII :

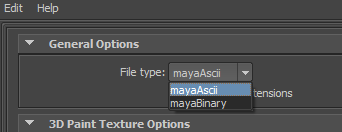
Contrairement au binaire, ce mode permet de sauver sa scène sous forme d’un gros script lisible pas tout bon éditeur de texte (ouvrez la scène sauvegardée avec votre éditeur de texte favoris puis jugez) .
N’oubliez pas de cocher l’option Use full names for attributes on nodes. Comme vous le devinez, cette option affiche les noms complets des attributs.

Sauvez une scène avec l’attribut Smooth Mesh Preview désactivé et une autre avec l’attribut activé.
Ensuite, ouvrez votre outil de visualisation de différence de fichier (diff ou Meld sous Linux, WinMerge sous Windows, FileMerge sous Mac).
En version ligne de commande, sous Linux, cela donne :
$ diff /home/narann/test.ma /home/narann/test2.ma
2,3c2,3
< //Name: test.ma
< //Last modified: Fri, Jul 09, 2017 21:13:45 PM
---
> //Name: test2.ma
> //Last modified: Fri, Jul 09, 2017 21:13:57 PM
75a76
> setAttr ".displaySmoothMesh" 2;
188c189
< // End of test.ma
---
> // End of test2.ma
Si on enlève les dates en début de fichier et la dernière ligne, on obtient :
> setAttr ".displaySmoothMesh" 2;
L’attribut s’appelle donc « displaySmoothMesh » et n’est pas un booléen mais un entier. 
On ne va quand même pas s’arrêter ici vous ne croyez pas ? Vous n’avez pas envi de connaitre les valeurs possibles de cet attribut ?
Vérifions son type :
import maya.cmds as mc
print mc.getAttr("pSphereShape1.displaySmoothMesh", type=True)
# enum
Donc c’est un enum. Pour récupérer la liste des valeurs possibles via un enum il faut utiliser la commande attributeQuery avec l’argument listEnum :
print mc.attributeQuery("displaySmoothMesh", node="pSphereShape1", listEnum=True)
# [u'Base Mesh Only:Base and Smooth Mesh:Smooth Mesh Only']
On a donc :
Bon, ça c’était cadeau, histoire de pousser le truc un peu plus loin mais l’idée de base, c’est de faire une différence entre les fichiers. 
 Un billet pour expliquer un truc assez bête mais qui fait perdre la tête à pas mal de gens tant il est obscur. Je vais parler de la notion d’unité de mesure dans les logiciels, ou pourquoi elle n’aurait peut-être jamais dû exister.
Un billet pour expliquer un truc assez bête mais qui fait perdre la tête à pas mal de gens tant il est obscur. Je vais parler de la notion d’unité de mesure dans les logiciels, ou pourquoi elle n’aurait peut-être jamais dû exister.
En début de production on tente souvent de se mettre d’accord sur un référentiel de mesure. La grande question est : « Quelle distance fait 1 ? », C’est-à-dire, quand un objet se déplace de 1 dans mon logiciel, à combien cela correspond-il dans le monde réel ? 
Avant de rentrer dans le vif du sujet, voici un topo rapide des différents référentiels d’unité utilisés.
Cette mesure permet de gérer de grands espaces mais fait souvent pester l’équipe modeling props qui, dans le cas d’un projet manipulant des dimensions de taille humaine, va se retrouver avec des 0.15, 0.47, etc pour dimensionner ses objets.
Cette mesure, pratique pour l’équipe modeling devient délirante lors de décors de plusieurs km. 1 km = 100 000 cm… À même pas 500 m vous risquez d’avoir des erreurs dû à la perte de précision des chiffres flottants dans les grandes valeurs (en version courte : Plus le chiffre avant la virgule est grand, moins il y a de place pour le chiffre après la virgule ).
Un référentiel que j’ai souvent observé et qui est un bon compromis est 1 unité du logiciel = 10 cm dans le monde réel (1 dm).
Ça permet d’avoir un bon équilibre entre des unités proches de ce qui est manipulable par les humains, 1 mètre du monde réel correspondant à 10 unités, et des unités larges de décor.
Et bim ! Dans le panneau !
La chose à comprendre est que, dans de nombreux cas, les nombres sont stockés sans référentiel. Ainsi, si vous avez un Alembic avec un cube de 1 sur 1, il est impossible de dire s’il s’agit de mètres ou de centimètres. C’est juste un cube de 1 sur 1.
Alors forcement, vous me répondez : « Bah si ! J’ai dit à mes équipes que 1 unité = 1 m, donc le cube est à 1 m. »
Vous en êtes sur ? 
Si vous aviez les capacités d’inspecter les valeurs à l’intérieur de votre Alembic, vous verriez… 100 sur 100.
« Mais pourquoi ?! » me demandez-vous ? Après tout, vous avez créé un cube de 1 sur 1, pas de 100 sur 100, vous l’avez vu, de vos yeux vu ce « 1 ».
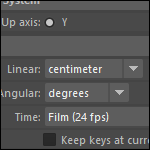
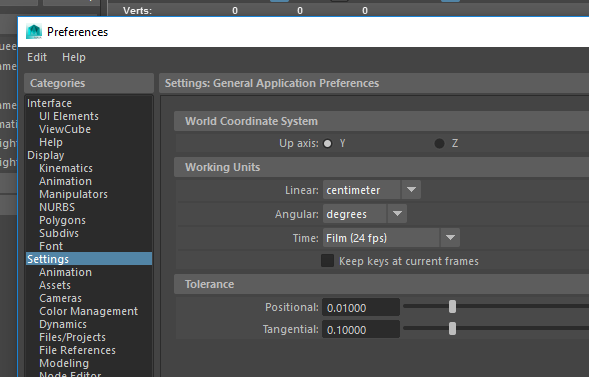
Et bien tout simplement parce que l’unité native de Maya c’est le centimètre. 
Si vous le réimportez dans Maya (configuré en mètre), il fera 1 sur 1, bien que les valeurs stockées soit 100 sur 100.
On a donc quelque chose d’assez déroutant et un peu dangereux : Si vous modifiez la mesure par defaut, les unités vues ne sont pas les unités stockées. Ainsi, si vous faites un décor de 1 000 m, vous aurez des soucis de précision, car les valeurs stockées dans l’Alembic et la géométrie seront en fait beaucoup plus importantes.
Vous l’aurez compris, dans Maya, 1 unité est toujours égale a 1 cm, le reste, ce n’est que de l’affichage. Dès que vous changez la mesure, vous entrez dans des prises de tête sans fin entre vos graphistes : « Mais puisque je te dis que j’ai exporté un cube de 1 sur 1 regarde ! Là dans Maya c’est 1 sur 1 ! C’est ton logiciel qui fait n’importe quoi en important un cube de 100 sur 100 ! Faut que t’appelles le support ! Moi c’est bon et toi t’as tort ! ». Vous voyez le genre.
Quand on quitte son unité native, Maya créé aussi toutes sortes de nœuds unitConversion, et bon nombre de valeurs par défaut deviennent absurdes.
La plupart des logiciels gèrent très mal les unités de mesure qui ne sont pas les leur. Il est donc conseillé de ne jamais toucher aux unités de mesure native d’un logiciel, par contre, il faut connaître la différence de référentiel entre les logiciels car, devinez quoi ?… Il n’y a pas de standard dans l’industrie ! 
Par exemple :
(Tu sens la prod qui va très bien se passer. )
Ça implique une chose : Toujours avoir en tête à quoi correspond « 1 » quand on le voit dans les Alembics, les AOV de position, les fichiers textes de position, etc. En gros, combien vaut une distance de « 1 » dans les données que vous produisez.
Il vaut mieux penser les unités comme des données et non comme des mesures, chaque logiciel ayant sa propre façon de percevoir cette unité.
En pratique, Houdini ingurgite principalement des Alembics :
Et vous êtes tranquille.
Notez que vous pouvez gérer l’unité de mesure de Houdini dans les préférences : Hip File Options. Il y est précisé que seul certains paramètres des DOPs (Dynamic OPerators) semble se soucier de l’unité de mesure.
C’est donc souvent autour de Maya que les choses tournent. Quand vous vous dites « 1 unité = 1 trucomètre », pensez « 1 cm Maya (mesure native) = 1 trucomètre ».
Houdini va pouvoir se débrouiller et bien souvent le problème viendra des logiciels qui fabriquent des objets en dehors de Maya (ZBrush, etc.). Une fois dans Maya ses objets permettront de définir la différence de référentiel par rapport à Maya (et donc, la différence de référentiel par rapport à votre unité).
TL;PL : Laissez Maya dans son unité de mesure native et travaillez comme si 1 unité Maya = 10 cm.