Geler les rigs en production
dimanche 17 avril 2022 à 17:50 Ce billet aurait pu être sous-titré : « Se tirer une balle dans le pied, mais rester debout ».
Ce billet aurait pu être sous-titré : « Se tirer une balle dans le pied, mais rester debout ». 
Le gèle des versions du rig (et du reste, d’une façon générale) est une question qui revient régulièrement au cours d’une production. Nous allons voir en détail pourquoi est-ce qu’il s’agit d’un problème insoluble (bah ouais… Sinon on en parlerait plus…  ) et avec de nombreuses ramifications qui nécessitent d’être comprises si on souhaite contenir leurs effets.
) et avec de nombreuses ramifications qui nécessitent d’être comprises si on souhaite contenir leurs effets.
Qu’entend-on par « geler une version » ?
Un paradigme récurrent dans un pipeline d’animation est la capacité à pouvoir gérer des versions « nommées ». Par exemple, on aurait des versions :
- toto_rig.v1.mb
- toto_rig.v2.mb
- toto_rig.v3.mb
Mais également :
- toto_rig.latest.mb
- toto_rig.release.mb
- toto_rig.FIXURGENTSHOT10.mb
Les versions numérotées n’ont, en principe, pas vocation à être modifié. La « v3 » dans six mois est supposé être le même fichier que lors de sa publication. 
Ce n’est pas le cas des versions « nommées » :
- « latest » serait logiquement défini comme pointant systématiquement sur la dernière version.
- « release » sur la version « à utiliser en production ».
- « FIXURGENTSHOT10 » une version spéciale visant à résoudre un problème bien spécifique (ce n’est pas propre, mais un tel mécanisme permet cela).
- etc.
Ces versions « nommées » sont, en quelque sorte, des définitions de ce qu’est la version :
latest -> v6
release -> v3
OMAGADSHOT10IZDOWN -> v4
Notez que ces concepts peuvent exister, même si les choses ne sont pas formalisées de la sorte. Par exemple, si un studio n’a pas d’outils pour gérer des versions nommées, il peut le faire en sauvegardant systématiquement la dernière version du rig sur la « v1 » (le fichier toto_rig.v1.mb). Ainsi, la « v1 » peut être considéré comme la « latest » et on ne créera une « v2 » que si le rig change au point de casser les scènes d’animations ; par mise à jour des noms et/ou comportements des contrôleurs.
Dans tous les cas, ces versions (dites « nommées ») ont pour vocation d’être mises à jour et modifiées, sans imposer à ceux qui en dépendent de repointer dessus ; si votre scène pointe vers toto_rig.latest.mb, vous aurez toujours la dernière version. C’est une propriété qui permet d’éviter une gestion granulaire des versions quand la balance entre les conséquences négatives d’une mise à jour de version et le temps économisé par le fait que cette mise à jour soit automatique et instantanée penche en faveur du second.
Traduisez : Si toutes les scènes utilisent « latest » et qu’on choisit de republier (donc, de modifier « latest ») une version qui n’a aucune conséquence sur le comportement du rig (au-delà de corriger, le bug), alors c’est une option valable pour corriger rapidement un rig partout où il est utilisé. Idem pour « v1 », si on choisit de la ré-écraser.
Ce que j’essaye de dire, c’est qu’en pratique il n’est pas forcément nécessaire de pointer vers des versions nouvellement publiées ; quand on se débrouille bien, avoir une version « latest » en référence des scènes d’animation est possible.
Toutefois, il vient forcément un moment ou ce mécanisme, si économique, joue en votre défaveur.
Il arrive un moment où cette version, ici « latest », doit pointer vers une version qui ne changera plus avec le temps, la version numérotée vers laquelle elle pointe. On parle alors de « geler la version ».
Pourquoi a-t-on besoins de geler les rigs ?
Même si la réponse arrive d’elle-même en cours de production, il est intéressant de regarder comment les choses se passent avec un exemple concret.
Les parties exposées du rig (ses contrôleurs et attributs) doivent avoir un comportement identique d’une version à l’autre.
Par « comportement identique », j’entends : À valeurs d’attributs et de positions égales entre les deux versions le rig, le résultat dans la scène doit être le même ; la géométrie des objets ne doit pas changer.
En cours de production, cela nous donne :
Les scènes d’animation utilisent une version d’un rig (en référence ou non). Pour cet exemple : La « release » au moment de la génération de la scène, qui pointe disons, sur la « v1 ».
Plusieurs animateurs commencent à animer leurs plans et à les faire valider.
Viens ensuite le moment que tout rigger redoute : Le comportement de base du rig est problématique, et les animateurs passent beaucoup de temps à se battre contre celui-ci pour obtenir ce qu’ils veulent. Il faut modifier le rig pour le bien du reste de la production.
À ce stade, des animations ont été commencées avec un rig donné (la version « release », qui pointe sur la « v1 ») et certaines animations sont peut-être déjà validées.
Il faut créer une nouvelle version du rig en s’assurant que le comportement (le résultat de la pose pour des attributs donnés) ne changent pas. 
Plusieurs approches sont possibles suivant la nature le la-dite mise à jour :
La nouvelle version ne change rien au comportement du rig. Ce sont souvent des mises à jour mineurs ; ajout d’un tag sur une shape pour le rendu ou l’export, modification des couleurs des vertices, parfois même une correction d’UV, etc.
Dans une telle situation, vous pouvez changer la version du rig sans que cela influe sur la géométrie et/ou l’animation. Vous pourriez presque écraser la version…
C’est le cas le plus simple à gérer, mais aussi le plus rare.
Une nouvelle version de rig peut aussi se retrouver à ajouter des fonctionnalités. Ce cas est la voie à privilégier lors de la création d’une nouvelle version de rig. C’est sûrement pour cela que c’est, d’après moi, le cas le plus fréquent.
L’idée de base est que cette nouvelle version ne modifie pas le comportement du rig, sauf si on active des choses (qui sont désactivées par défaut). Il s’agit parfois d’ajouter des petits contrôleurs optionnels qui n’était pas présent avant, pour donner plus de contrôle à l’animation ; modifier l’épaisseur des bras, du cou, etc.
Cette méthode peut avoir le désavantage de surcharger le rig, mais est largement compensé par le fait qu’elle ne nécessite pas de discussion avec les équipes d’animation : Comme le comportement est désactivé par défaut, il ne change rien au résultat de ce qui est déjà en prod, et peut être déployé partout sans conséquences.
On a alors « augmenté » le rig. Quand on a une modification à faire en cours de production, il peut être intéressant de privilégier cette approche, quitte à ce qu’elle impose plus de tests.
Optionnel : Suivant la nature de la modification (et si votre pipeline le permet), vous pouvez activer l’attribut (le nouveau comportement) lors de la création des nouvelles scènes d’animation, ce qui permet aux animateurs de ne pas avoir à le faire. Ils vous feront des bisous, vous enverront des chocolats et inonderont votre profil LinkedIn de chants à votre gloire.
 Dernier cas : La nouvelle version de rig casse l’animation.
Dernier cas : La nouvelle version de rig casse l’animation.
Ça y est, on est dans le fond du problème : Le comportement des attributs a changé. Mettre cette version en production casserait l’animation. Le gel des versions du rig est votre seule sortie.
Arrivé ici, il est rare qu’on puisse s’en sortir sans conséquences désagréables, et c’est souvent la raison pour laquelle vous aurez à vous poser la question du gel des versions du rig en animation.
Éviter le problème ?
Avant d’aborder les stratégies pour minimiser l’impact d’une telle mise à jour, je dois aborder comment l’éviter.
Si vous lisez ce billet, il est possible que les quelques lignes qui suivent ne vous aident pas énormément, mais je suis obligé d’en parler. 
La technique qui permet de diminuer drastiquement les problèmes de rig c’est déjà de les tester au maximum avant leur entrée en production. Si ce n’est pas systématique, les superviseurs anim ne sont pas forcément les plus amènes de remonter des problèmes pertinants. Du fait de leurs responsabilités, ils passeront plus de temps à organiser le travail des équipes, que le nez dans les scènes à animer des plans. Ils auront alors le réflexe de faire des remarques générales sur le comportement du rig. Il est donc important que des leads (ou personnes supposées devenir lead à la suite de la production) puissent également faire des retours. Ces derniers ayant une approche de support (de leurs graphistes), ils se poseront beaucoup plus la question de ce qui est fatiguant au quotidien, autant pour les équipes que pour eux.
Leur feu vert garantis à la production que le département de rig ne soit pas le seul à supporter la responsabilité d’un problème. Si le rig est considéré comme mauvais parce qu’on découvre un problème qui aurait pu être détecté par les animateurs avant le début de la production, le problème ne vient pas du rig, mais du manque de tests de l’animation. Un rigger n’est jamais un utilisateur de ses propres rigs, et malgré l’expérience, rien ne remplace un retour après plusieurs heures d’utilisation.
Un moyen très pratique de rentabiliser ce temps de travail/test est de mutualiser la fabrication des rigs (souvent via un auto-rig), afin qu’ils soient similaires et aient les mêmes options et comportement. Ce qui revient à doubler l’argument celons lequel les tests de rigs sont importants, car ils ne servent pas qu’à un seul rig, mais à tous les rigs à venir.
Mais c’est un autre sujet. 
Stratégies
Il y a plusieurs façons d’éviter le drame d’une mise à jour de rig qui détruise l’animation. 
Si vos scènes d’animations pointent vers des versions nommées « release », ou « latest », il va falloir trouver un moyen de définir que ce n’est plus vraiment le cas.
Un gel de version a des implications importantes et c’est le choix de quand vous le faites qui est déterminant. Dis autrement : C’est le moment, dans votre pipeline, ou vous choisissez de geler une version qui va déterminer la façon dont vous allez vous y prendre.
Imaginons la situation suivante :
- Votre version « release » pointe sur la « v1 ».
- Vous souhaitez publier un rig « v3 » que vous voulez passer en « release ».
Notez qu’afin de ne pas complexifier mon exemple, je ne parlerais pas de la version « latest », mais la logique est similaire.
La méthode brute consiste à ouvrir toutes les scènes d’animation et changer la référence de « release » vers « v1 », puis de republier une scène de travail. Cette méthode vous garantit qu’un animateur ouvrant sa scène aura le même rig que ce qu’il avait au moment où il a arrêté son travail, même si « release » change entre-temps.
Cette méthode peut fonctionner dans des petits groupes, mais est difficile à mettre en place dans des grosses structures. 
Une autre méthode consiste à stocker la version à laquelle correspondait la version « release » dans chaque publication. En gros, vous laissez la version d’animation pointer vers « release », mais vous mettez, en métadonnées de la version de la scène d’animation, la version vers laquelle « release » pointe. Ainsi, après ouverture de la scène avant export de l’Alembic vous forcerez la version du rig à utiliser.
Ceci a les effets suivants :
- L’Alembic exporté est garanti d’utiliser la version du rig qu’avait l’animateur au moment de sa publication.
- Les scènes d’animations vont casser au moment de l’ouverture, laissant l’animateur la capacité de corriger l’animation. Ou, via un petit outil, un moyen de repointer vers la « v1 », en dur.
Cette méthode assume que le problème du rig est bénin à corriger pour l’animateur et que ce dernier va immédiatement voir le problème. Or il est tout à fait possible que :
- L’animateur, réouvre sa scène pour un correctif en fin (de timeline) d’animation.
- Ne remarque pas que la mise à jour a cassé le mouvement en début d’animation.
- Republie sa scène pointant vers la dernière version actuelle (« release » en « v3 »).
Ceci qui aura pour effet de publier, en métadonnée, le numéro de la version qui ne fonctionne pas en début d’animation (« v3 ») et de propager le problème dans l’Alembic.
Quand je vous disais qu’il n’y a aucune solution miracle… 
Voici ma solution, imparfaite, qui semble fonctionner « en pratique » :
- Le rig doit savoir quand une version cassera l’animation/le comportement de la précédente.
- Le rig peut livrer sur n’importe quelle version (il n’est pas obligé de systématiquement publier une version v+1, mais peut écraser une version existante).
- Les scènes d’animation pointent vers des versions absolues ; v1, v2, etc.
- Les nouvelles scènes d’animation pointent vers la dernière version du rig au moment de leur création.
Avec cette approche, c’est le rig qui est responsable de ce qu’il livre et de quand il choisit de faire monter une version.
Comme je le disais, ce système est imparfait, car il oblige une organisation plus fine du rig : Ce dernier peut être amené à faire un correctif non-destructif sur une v1, alors qu’on est sur une v4 depuis des mois, d’où l’importance de votre pipeline à stocker et exposer facilement aux graphistes les dépendances de fichiers.
Dans tous les cas, ce système est loin d’être parfait. Certains pipelines sont conceptuellement incapables de réécrire sur une version au fil de temps. C’est au cas par cas.
Le gel des versions, un problème plus vaste
Vous l’aurez deviné, la problématique du gel de versions est un problème très vaste qui n’a aucune solution miracle :
- Modélisation : Peut-on republier une version d’un objet quand des plans sont déjà commencés avec, et sont calé de façon très fine ?
- Décors : Peut-on republier une version d’un décor en déplaçant des objets qui normalement ne sont pas supposés être modifié par l’animation ?
- Rendu : Est-ce que je gèle les versions de tout ce que j’ai en entré (c’est une bonne pratique) et si oui, quand ? En check assemblage ? À la preview ? Après la preview ? Et comment gérer les mises à jours parfois nécessaires ?
Chaque département a ses propres logiques qui va dépendre de l’organisation du studio et de son pipeline qui tentent de trouver un équilibre entre la flexibilité et la granularité de la fabrication.
J’espère que ces lignes vous auront ouvert à la complexité de ce problème et vous aideront à proposer des solutions à vos équipes. J’ai mis énormément de temps à sortir ce billet, car comme vous vous en êtes rendu compte, les embranchements sont importants, mais il me semble que c’est le b.-a.-ba. d’un rigger que de gérer (c.à.d., limiter) ce genre de situations.

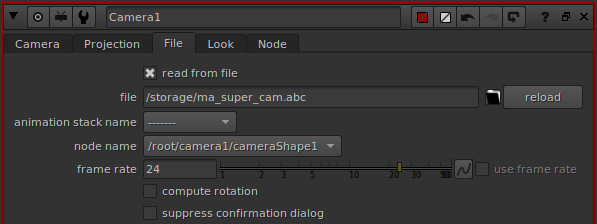
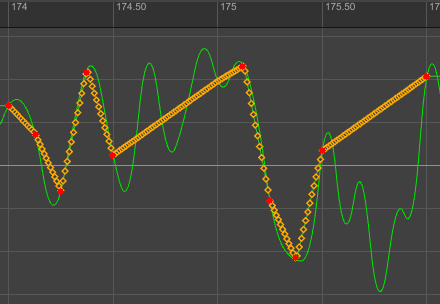
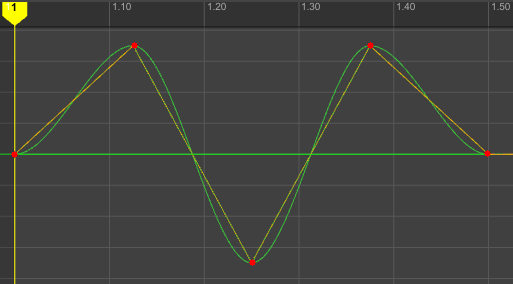
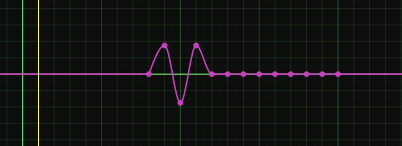
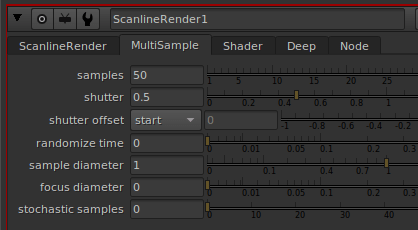
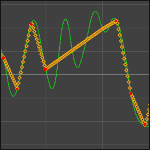 Avez-vous déjà eux des problèmes de rendu dans Nuke en utilisant des caméras ayant des sous-samples ?
Avez-vous déjà eux des problèmes de rendu dans Nuke en utilisant des caméras ayant des sous-samples ? 





 ).
).











 Depuis la version 2.3.9, Guerilla dispose d’un log de rapport de contributions des lights de vos scènes. Il n’est pas évidant d’interpréter correctement ces valeurs : Elles ne sont pas forcément simples à comprendre, et encore moins à mettre en relation avec l’image.
Depuis la version 2.3.9, Guerilla dispose d’un log de rapport de contributions des lights de vos scènes. Il n’est pas évidant d’interpréter correctement ces valeurs : Elles ne sont pas forcément simples à comprendre, et encore moins à mettre en relation avec l’image. 



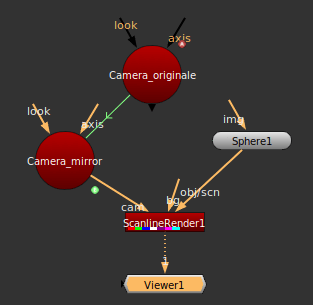
 Un plan, une sphère, deux lights positionnées à 180 l’une de l’autre et un mur sur celle de droite :
Un plan, une sphère, deux lights positionnées à 180 l’une de l’autre et un mur sur celle de droite : Le rendu :
Le rendu : Clairement la light derrière le mur ne contribue pas au rendu, et les statistiques le confirme :
Clairement la light derrière le mur ne contribue pas au rendu, et les statistiques le confirme :
 Rendu avec une seule light, à droite :
Rendu avec une seule light, à droite : On remarque que Guerilla n’arrive pas à sampler une partie de l’image. Et pour cause, aucune light n’illumine ses zones.
On remarque que Guerilla n’arrive pas à sampler une partie de l’image. Et pour cause, aucune light n’illumine ses zones.  Il y a plein de façons de faire de l’ambiant occlusion.
Il y a plein de façons de faire de l’ambiant occlusion. 




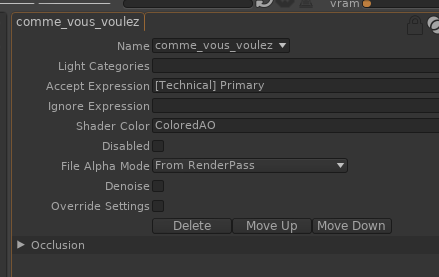
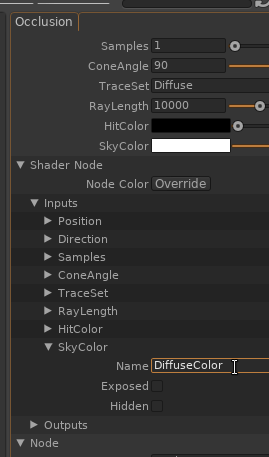
 Renommer « Value » par un nom perso « ColoredAO » :
Renommer « Value » par un nom perso « ColoredAO » :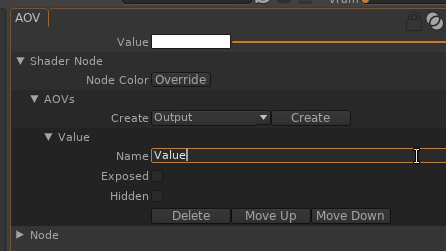

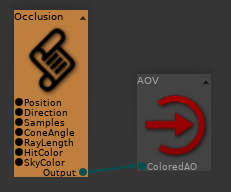



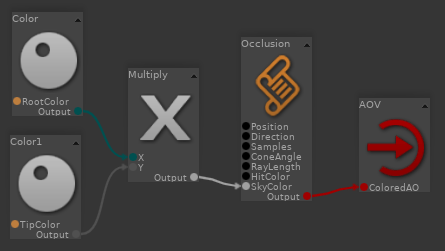
 Et sous vos yeux ébahis :
Et sous vos yeux ébahis :

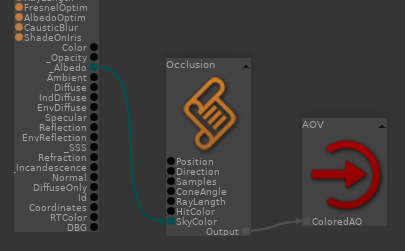
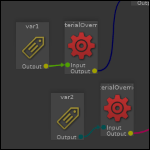 Dans ce billet, je vous propose une méthode pour gérer les variations de lookdev. Nous allons voir que la notion de « variation » est un concept assez flou tant il peut rapidement impacter tous les départements. En pratique, il peut y avoir plusieurs méthodes, chacune ayant ses spécificités.
Dans ce billet, je vous propose une méthode pour gérer les variations de lookdev. Nous allons voir que la notion de « variation » est un concept assez flou tant il peut rapidement impacter tous les départements. En pratique, il peut y avoir plusieurs méthodes, chacune ayant ses spécificités. 




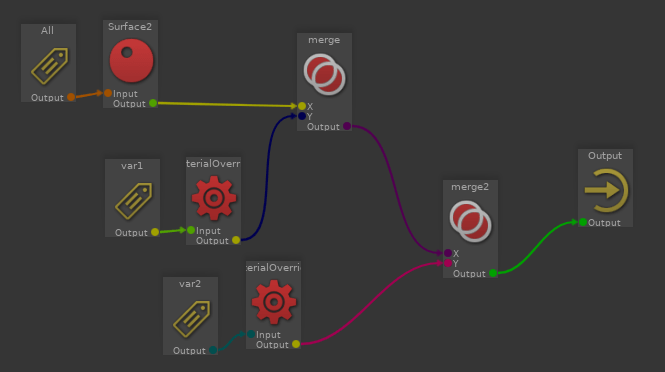
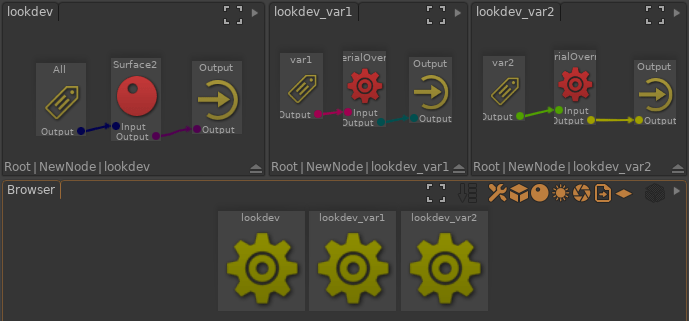
 ), mais c’est un cas classique de « contorsion du pipeline » : Ont fait rentrer un nouveau type de problèmes en se servant d’un mécanisme existant et fiable, mais de façon peu élégante. Ce genre de bricolage peut être courant sur des gros pipelines de production (avec parfois, des outils dédiés !).
), mais c’est un cas classique de « contorsion du pipeline » : Ont fait rentrer un nouveau type de problèmes en se servant d’un mécanisme existant et fiable, mais de façon peu élégante. Ce genre de bricolage peut être courant sur des gros pipelines de production (avec parfois, des outils dédiés !).