Je me suis rendu compte que j’ai oublié de parler de deux-trois choses dans mon billet précédent et je suis parfois passé trop rapidement sur certains points.
Je vous propose un billet d’appoint pour corriger le tire, ce sujet aux branchements infinis le mérite bien. 
Aujourd’hui, je comparerai l’approche automatique et semi-manuel pour gérer les LOD géométriques, j’aborderai la relation entre le département de modeling et de lookdev puis on finira par les poils.
Système automatique
Avant propos
Si c’est la production ou la supervision qui met le sujet sur le tapis, il est probable que ce soit avec l’idée d’en faire un truc « automatique et transparent pour l’utilisateur », ce qui, ironiquement, correspond à la définition d’un truc « magique et opaque ».
Il va de soi que plus le projet est ambitieux, plus l’automatisation est importante, personne ne veut voir ses graphistes passer leurs journées à faire des opérations rébarbatives à la main. Et pourtant…
En pratique l’ajout de LOD géométriques dans vos projets veut dire que vous faites intervenir, dans vos tuyaux/scènes, une « particularité » de vos assets. Ainsi, même si vous automatisez la gestion des LOD, ces derniers ne disparaissent pas, vous ne les voyez simplement plus, jusqu’à ce qu’ils posent problèmes. Vous me répondriez : Pourquoi diable voulez-vous qu’ils posent problèmes, car leur gestion est « automatique et transparent pour l’utilisateur » ? 
Cette perception nie la nuance. En effet, on ne fabrique pas des plans comme on fabrique des objets dont l’essence est d’être identique (agroalimentaire, informatique, jouets, etc.). La « nature » des plans varient. Par nature, j’entends ce qui en détermine sa fabrication ; un plan de visage a ses propres problématiques de fabrication (SSS des yeux/cou/vêtements, cheveux, Rim light, arrière-plan, etc.), de même qu’un plan de décor (nombre d’objets, lookdev d’ensemble, matte painting, etc.). Les deux ne se fabriquent pas de la même manière et la pertinence d’utiliser des LOD ou non en est très dépendante. D’une manière générale, plus on pousse la qualité vers le haut, plus des contrastes assez net s’opèrent dans la façon dont les plans sont fabriqués.
On commence à comprendre pourquoi les LOD, prétendument automatiques, reviennent toujours sur le tapis. Les graphistes travaillent avec un ensemble de choses simples (Alembic d’animation, assignation de lookdev, surcharge des positions/attributs, etc.) qui s’entremêlent, formant un tout complexe. Le rendu est le plus touché car c’est le département qui rassemble tout. Si la gestion des LOD est automatique et qu’ils ne sont donc pas explicitement « choisis » par les graphistes, ces derniers devront les ajouter aux potentielles raisons des problèmes qu’ils ont sous les yeux.
La production (et dans une certaine mesure, la supervision) a parfois du mal à juger de cet effet indirect.
Après ce (trop) long aparté, rentrons dans le vif du sujet : À quoi faut-il penser quand on automatise la gestion des LOD ? 
Concrètement
Je pars du principe que vous êtes un TD à qui on a refilé la patate chaude et que ni le modeling, ni le lookdev ne veut intervenir (« transparent pour l’utilisateur » toussa).
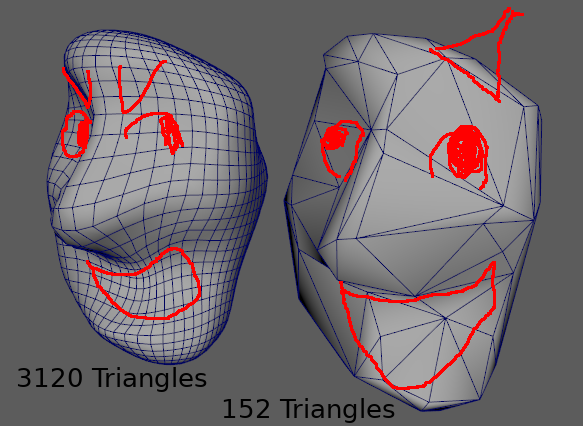
L’approche naïve consiste à prendre toutes les géométries de sa scène et de leur appliquer un gros Reduce. Le résultat est très moche, mais a priori, c’est pas le sujet. 
Comme dit dans mon billet précédent, il faut s’assurer que les UV de la géométrie réduite ne soit pas détruits et correspondent à la géométrie originale.
Le plus gros problème c’est taille de la hiérarchie. Si elle est trop grosse, vous pourriez vous retrouver avec des milliers d’objets qui ne font chacun que deux ou trois polygones. Suivant vos méthodes de travail il est fort probable qu’une fois instancié des milliers de fois, vos logiciels de lookdev pédalent à traverser la hiérarchique de vos LOD.
On pourrait être tenté de supprimer les petits objets (petites bounding boxes) mais si c’est ce qui compose l’ensemble de votre asset (e.g. un arbre, une plante), vous risqueriez d’en supprimer une partie visible importante et vous retrouver avec un asset tout nu ce qui peut mettre le modeleur mal à l’aise devant son superviseur :

Si vos superviseurs modeling et lookdev sont de connards qui ne veulent rien entendre, il vaut mieux éviter les LOD. Si vous ne pouvez pas intervenir sur cette décision, vous êtes foutu. Vous pouvez mettre à jour votre Linked’In et commencer à postuler ailleurs, car les départements rendus vont pleurer du sang.
Mais on est dans le vrai monde, celui des Bisounours et des glaces à la vanille, celui ou les superviseurs comprennent les intérêts des solutions que vous leur proposez, pour peu que vous leur parliez lentement.
Ce qui m’amène au second point : La méthode semi-manuel. 
Système semi-manuel
Aider les graphistes par « contrat »
Au passage, appelez-la semi-automatique, c’est plus facile à vendre à la production… 
Cette approche vise à résoudre les problèmes précédents par « contrat » avec les graphistes. Dans le cas de la hiérarchie trop dense, vous pouvez proposer la chose suivante à votre graphiste :
« Si ton groupe de nœuds porte le suffixe « _combined », le contenu sera combiné à l’export et le suffixe sera supprimé. »
En gros, vous garantissez que la hiérarchie suivante :
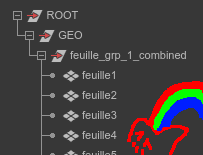
Sera converti en ça :
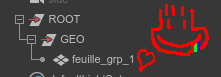
La confiance n’excluant pas le contrôle, vous n’aurez qu’à ajouter un sanity check s’assurant que chaque groupe suffixé « _combined » ne contient que des géométries et sans attributs, ces derniers étant perdu lors du combine.
Cette approche à l’avantage de laisser le graphiste contrôler la livraison de son travail par simple renommage des nœuds, directement dans Maya et c’est le code qui s’occupe de la partie rébarbative, le sanity check s’étant assuré qu’il ne puisse pas y avoir de surprise.
Il y a fort à parier que les personnes au lookdev y trouveront un intérêt en proposant des modifications au modeling, voir, en les faisant elles-mêmes. 
Cette approche par contrat implique de rester aussi simple que possible. La raison est que le graphiste peut se débrouiller tout seul en cas de problème sans que les outils d’automatisation ne soient un obstacle à la compréhension. Un réflexe que peuvent avoir les TD qui ne sont pas graphistes de formation est de trouver dommage de limiter le graphiste à ses propres compétences, là ou des supers outils, tout d’héritage de classes vêtus, pourraient l’aider à une échelle supra luminique. C’est vrai, jusqu’à ce que les TD deviennent les seules personnes à comprendre le travail des graphistes. Si vous ne laissez qu’un contrôle partiel à ce genre de contrat, vous « prenez » l’autonomie du graphiste sur des taches qui devraient rester sous sa responsabilité et que, par conséquent, il doit parfaitement comprendre, en vu de l’assimiler en tant que méthode. Vous voyez que vous êtes sur la bonne voie quand les graphistes développent de nouvelle façon de travailler tout seul, en s’appuyant sur ces « contrats ». Pour cela, il faut que ces derniers soient simples. 
Dans un pipeline, certaines choses sont humainement infaisables, c’est là-dessus que votre cerveau doit être créatif. Accélérer le travail du graphiste implique de se mettre sous sa perspective. Ce sont des erreurs d’estimation qui peuvent coûter cher. 
Il est plus facile de faire tout ça via des jobs d’export Alembic, car vous n’avez pas à mettre une logique de « retour à l’état précédent » une fois la scène modifiée ; vous ouvrez, vous modifiez, vous exportez, vous quittez.

Mais ne nous arrêtons pas en si bon chemin…
Les close up
Au même titre qu’une version basse définition, il peut arriver que des projets nécessitent des versions « high » (ou close up). Les toits des bâtiments par exemple. Vous pouvez « résoudre » la hiérarchie du graphiste suivante :
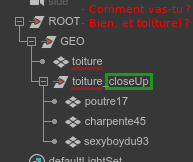
Vous pouvez procéder de plusieurs façons. La méthode bourrine consiste à tout exporter dans un seul Alembic. C’est l’assembleur (ou le graphiste au rendu) qui s’occupera de cacher l’un ou l’autre au besoin (via une petite expression par exemple), la version close up est caché par défaut.
Disons que c’est mieux que rien, mais ce n’est pas comme ça que l’on brille en société.
En effet, il est dommage de se trimbaler de la géométrie close up dans tout le pipeline, même si cette dernière est cachée. Il nous faut donc procéder à deux exports.
Vous pouvez proposer un contrat en deux clauses :
- « Durant un export standard, tout groupe contenant le suffixe « _closeUp » est supprimé. » (on supprime les géométries de close up de l’export de base)
- « Durant un export close up, toute géométrie ayant un homologue portant le suffixe « _closeUp » est supprimé. » (non, non, je n’ai rien oublié, lisez la suite)
Le résultât d’un export standard sera :
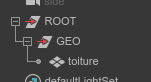
En celui d’un export close up sera :
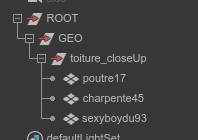
Pourquoi ne pas avoir renommé « toiture_closeUp » en « toiture » ? Ce serait, en effet, plus logique, mais, dépendant de votre façon de gérer les assignations, cela risquerait de couper l’herbe sous les pieds du lookdev qui peut avoir besoin de faire la distinction entre l’objet « toiture » et le contenu de « toiture_closeUp ».
Mais ça, c’est quand votre logiciel de lookdev c’est du caca (ou que vous ne savez pas l’utiliser  ).
).
Vous pouvez contourner ce problème en s’appuyant sur les rangées des UDIM :

Ainsi, vous gardez le contrôle via textures, indépendamment de la hiérarchie. Gardez toutefois à l’esprit que compenser l’accès à la géométrie par des UDIM implique que la moindre retake de lookdev nécessitera un export de texture, ce qui amène à des situations qui défient l’entendement : Là ou diminuer le spec ou la diffuse pourrait se faire en un override sur l’objet en question, vous devez ouvrir votre projet Mari/Designer/Toshop, faire la modification et exporter avant de pouvoir tester. La limite entre une gestion par override et une gestion 100 % texture est un sujet à part qui mériterait son propre billet, mais je vais fermer la parenthèse. 
Si votre logiciel de lookdev vous permet de faire la distinction d’assignation entre « toiture » et « toiture|poutre17 », alors il ne faut pas se priver et faire en sorte que la version close up prenne la place de la hiérarchie originale :
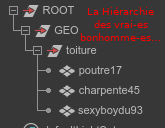
Comme ça, si le rendu fait une expression pour modifier « toiture », cela fonctionnera, que le modèle soit en close up ou non.
Mais, bordel de m*  , on peut aller encore plus loin !!!
, on peut aller encore plus loin !!! 
Le merge de hiérarchie
Si vous avez Katana, vous pouvez opérer un merge exclusif entre deux hiérarchies. Si A est la hiérarchie standard et B la hiérarchie close up, vous pouvez demander à Katana de « superposer » les hiérarchies en choisissant la hiérarchie B en cas de conflit.
Ça veut dire que votre Alembic de close up ne contient plus que les nœuds ayant précédemment le suffixe « _closeUp », sans les géométries standards, car la hiérarchie de close up est tout le temps combiné (mergé) à la hiérarchie standard.
Je ne sais plus du tout comment on fait ça par contre, va falloir me croire sur parole. 
Autre point important qui rejoint le sujet des combines,
Sans aller jusque-là, je pense avoir pas mal poussé le truc pour vous donner matière à réflexion. L’objectif étant toujours de rendre les graphistes autonomes tout en leur proposant des « outils » (ce n’est peut-être pas le bon mot) qui correspondent à ce qu’ils font.
Dans tous les cas
Quelle que soit la méthode utilisée, tout ceci demande un travail supplémentaire, et avec les moteurs de rendu actuel, ce n’est pas toujours justifié.
Faire l’économie de la vérification de ce qui sort des tuyaux peut se payer cher plus tard. Il vaut mieux vérifier en amont (via tournettes) si les données générées sont propres et « rendent » bien, mais c’est encore un temps à passer à regarder des assets. Les LOD sont des objets internes à la fabrication. Jouez pas au con et ne présentez pas ça au réal…

Note sur le transfert d’UV
Là, on passe en manuel ! Donc nous allons parler de techniques à ajuster au cas par cas.
C’est une technique a priori un peu bancale mais c’est parce que je l’ai vu fonctionner que je vous la partage.
Des studios font faire les UV directement au lookdev au motif, tout à fait justifié, qu’il est le premier concerné par le résultat. Dès lors, vous avez un croisement entre les données générées par vos graphistes et l’ordre dans lesquels vous les produisez : Si le lookdev est censé faire les UV, mais que les LOD sont déjà fait par le modeling, comment assurer que les UV des LOD sont cohérents ?
Par le transfert d’UV pardi ! 
Je suis sûr qu’il y a des cas où ça foire (les arbres), mais les résultats sont convaincants si la géométrie des modèles basses définitions correspond à leur homologue en hautes définitions.
Ça nécessite quelques nuances dans l’organisation : La modé ne fait aucun UV, le lookdev qui les prends tous à sa charge. Il est important que la production ait cette information car ça nécessite un glissement des ressources vers le lookdev, ces derniers auront plus de travail par asset et mettront plus de temps à travailler. En revanche vous pouvez séparer le travail intelligemment en laissant le lookdev faire les UV des assets compliqués (personnages, bâtiments de premier plan, etc.) et laisser le modeling faire les UV d’asset de second plan (props, etc.).
Vous en voulez encore ?
Le TriPlanar
Celle-là je la sors de Guerilla, mais je suis sûr qu’on peut la déporter sur d’autres moteurs. Le principe est de faire plusieurs rendus de trois caméras (face, côté, dessus). Pour chaque rendu dont on exporte l’albédo, le masque le spéculaire et surtout, la normale. Guerilla permet de faire ça assez simplement (doc ici).
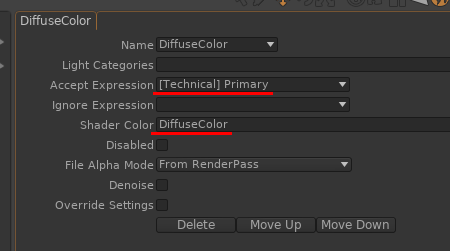
On fait ensuite un shader très simple (Couleur de diffuse + une couche de spéculaire grossière + la normale), une géométrie très simple (des cubes + un toit = 6 faces) et on a un asset très léger qui a un peu de gueule quand il y en a (vraiment) énormément. On est très proche du jeu vidéo (peu de poly, tout dans la texture).
Cette technique marche assez bien sur les bâtiments lointains (genre l’horizon d’un Paris…). Vous devriez pouvoir étendre le principe aux arbres (la vielle technique des plans superposées), mais je n’ai jamais testé.
Les transitions
Si vous utilisez un système qui permet de permuter un LOD suivant la distance et la caméra, et que vous faites ça sur une foule ou un amas (une forêt), il est probable que ce passage d’un LOD à l’autre entraîne un « saut » inesthétique entre les changements de LOD. 
Si vous avez la main sur le mécanisme de distribution, vous pouvez définir une zone, assez large dans laquelle les LOD sont mélangés au prorata de la distance. Admettons que vous voulez que la transition se fasse entre 100 m et 200 m. Pour un arbre à X m, vous calculez un random (entre zéro et un) multiplié par le ratio de X par rapport à 100 m et 200 m :
ratio = (X-100)/(200-100)
if ratio <= 0.0:
# high resolution
elif ratio > 1.0:
# low resolution
else:
# pseudo random choice
if random * ratio <= 0.5:
# high resolution
else:
# low resolution
La documentation du nœud le setRange. Je la regarde à chaque fois que j’ai un doute sur l’équation.
Faire une transition de LOD implique tellement de choses qu’il vaut mieux s’en passer autant que possible. Si votre plan est animé ? Tentez de gérer le tout en haute définition. En effet, le grain que vous souhaitez chasser via vos LOD (c’est le but après tout) risque de ne jamais être visible du fait du mouvement de caméra.
Si vous pouvez les éviter, alors faites-le. 
Subdivision et displacement
C’est tellement basique, mais je soupçonne que les logiciels permettant de gérer des lookdev en masse et le fait que les path tracer mangent du poly nous pousse à ne trop penser à la subdivision est au displacement. Pourtant, ça ne coûte pas grand-chose de couper sa subdivision et son displacement sur tout ce qui est éloigné ou peu visible de la caméra. Vous pouvez chercher toutes les méthodes de LOD du monde, si vous ne faites pas ça, ça ne sert à rien. 
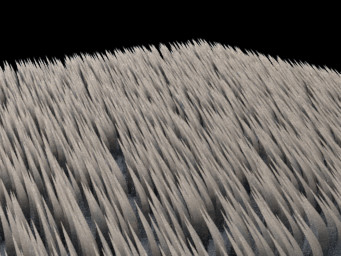
Les poils
Et nous arrivons à la raison pour laquelle je voulais vous faire ce second billet : J’avais oublié de vous parler des poils (fur/hair/Yeti/XGen, j’utiliserais le mot poil pour désigner cet ensemble). J’y vois deux gros cas de figures : Les poils des personnages principaux et les poils « statiques » (par arbre, par buisson, etc.).
Les poils « statiques »
Ils sont moins fréquents, mais le plus simple à gérer, car vous les considérez comme de la modé : Vous les générez une seule fois pour votre asset et vous l’instanciez comme une géométrie. Comme sortir un LOD de poil est assez facile, vous pouvez générer plusieurs versions et laisser les graphistes afficher l’une ou l’autre, l’idée étant d’éviter de générer ces poils par plan et par asset.
J’ai vu des graphistes utiliser cette méthode pour des buissons et arbustes d’un décor visible sur peu de plans. Plutôt que de s’embêter à faire une modélisation dédiée (quand on sait à quel point placer des feuilles est casse-pied), le superviseur a proposé de faire une géo de branche, instancié de gros poils dessus, cuire ça (via les ghostdata de Guerilla) puis l’instancier. C’est malin et terriblement efficace. Car ils ont pu faire plusieurs variations de formes de buisson assez différentes (rendu totalement différente par les couleurs du lookdev), mettre ça des milliers de fois dans un décor et ça tournait sans trop de difficultés.
Je vais aussi vous parler d’un problème difficile à déboguer. Il est peu probable que cela vous arrive, mais ce dernier ne sautant pas aux yeux, je trouve intéressant de vous en parler : Suivant le système de poil que vous utilisez (ici, Yeti, mais je pense que d’autres pourraient avoir le même problème), il est possible de l’utiliser pour générer la végétation de tout un décor. Votre moteur peut se faire avoir en assignant une bounding box unique à tout ce que la procédurale génère. En pratique, l’impact est négligeable, car les moteurs sont rapides. Mais il est toujours difficile de gérer tout un décor et les graphistes peuvent être tenté de faire leur dispersion d’éléments en couches (cailloux au sol, vielles branches, buissons, arbustes et enfin, arbres), voir par section du décor. Si vous avez six couches, vous avez six bounding box de la taille du décor qui vont être questionné inutilement pour chaque rayon. Et là ça commence à se sentir sur les performances.
Encore une fois, il est peu probable que vous n’ayez jamais à gérer un tel problème, mais c’est aussi un rappel à garder ses bounding box cohérentes.
Les poils « dynamiques »
Voila pour les poils statiques. Les poils dynamiques sont plus compliqués à gérer. Compliqués parce qu’ils sont souvent sur les personnages principaux, ce qui en nécessite beaucoup, à cela s’ajoute un shading complexe. Ces plans rentrent dans la farm comme un barbare dans un couvent de nonnes.
Je pense qu’il n’y a pas de solutions qui marchent à tous les coups, mais on peut s’éviter du sang et des larmes en gardant quelques réflexes dont je vais essayer de faire le tour.
Ce qui prend de la mémoire, c’est la géométrie, mais il est important de ne pas s’arrêter au nombre de poil, car la complexité de chacun peut drastiquement peser dans la balance.
Pour chaque poil:
Pour chaque point par poil (3 minimums pour une courbe):
la position (3 float) * step de motion blur (2 minimums)
la couleur (3 float)
Il est difficile de donner une équation parfaite, car les moteurs ont différentes stratégies que vous pouvez, plus ou moins, contrôler. Par exemple, vous pouvez (ou non) avoir des step de motion blur pour la couleur, voir ne pas avoir de couleur du tout, ou une seule couleur par poil, etc.
De plus, vous pouvez activer la compression ce qui influe encore sur le résultat. Pas de secret, il faut tester.
Pour ce qui est du temps de rendu, c’est le shading qui est le plus influant et autant on dispose de marge de manœuvre avec la géométrie (couleur, step de motion blur), autant le shading est plus capricieux car visible et toute modification visuelle risque d’entraîner des discussions difficiles. Si vous êtes superviseur, vous avez un rôle à jouer. Ne laissez pas vos graphistes les gérer seul, car ils peuvent baisser les bras et vous prenez le risque de partir en production avec des choses inrendables.
En vrac :
- La transparence coûte cher. Il vaut mieux biaisé en montant le nombre de poil que l’activer.
- Certains modèles d’illumination fonctionnement mieux avec les poils longs (cheveux) que les poils courts. Lisez les détails d’implémentation dans la documentation, parfois votre moteur propose d’autres modes.
- Vos poils ne pardonneront pas les inconsistances d’éclairage de vos scènes. Si votre lighting fait n’importe quoi, il y a fort à parier que vos poils y réagiront plus vivement que le reste des matériaux de votre scène.
- Et réciproquement, les bricolages de trace set peuvent être plus difficiles à généraliser.
- Éviter le SSS sous les poils, suivant vos optimisations, il est possible qui le calcul du SSS ne prennent pas en compte l’ombrage des poils, ces derniers étant supprimé du trace set de SSS. Vous avez le risque qu’un sample traverse les poils et renvoi un calcul d’illumination de la peau complètement biaisé qui formera une mouche.
- Les shader de poil sont complexes, évitez de mettre des textures pour tout et n’importe quoi, cela rend les problèmes d’illumination difficile à déboguer.
- Suivez les conseils de la documentation de votre moteur qui donne souvent de précieuses informations. Vous devez comprendre chaque paramètre et les privilégier.
- Faites des tournettes et ne laissez rien passer. Les tournettes ont souvent des éclairages très simple, si petit artefact apparrait, il est probable que vous ayez à vous le coltiner toute la production.
- Les env ball, c’est la vie, ne l’oubliez pas.
- Lisez la putain de doc !

D’une manière générale, vous devez maîtriser les shaders que vous utilisez en production, c’est encore plus vrai en ce qui concerne les shader de poil pour éviter de s’arracher les cheveux.
Croyez-le ou non : J’ai créé ce second billet avec l’ambition de vous parler de l’automatisation de la densité des poils au plan, mais le fil de mes développements lui ont donné une taille conséquente et ce sujet me semble suffisamment complexe pour mériter son propre billet, je vais donc m’arrêter là et je vous dis à bientôt !
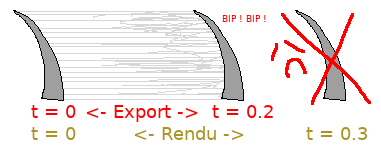
 Dans ce billet on va encore parler de poils et tout particulièrement du motion blur de Yeti dans Guerilla.
Dans ce billet on va encore parler de poils et tout particulièrement du motion blur de Yeti dans Guerilla.











 J’espère qu’avec ce billet je vais enfin terminer cette longue et indigeste série sur les LOD.
J’espère qu’avec ce billet je vais enfin terminer cette longue et indigeste série sur les LOD.  ), mais l’idée générale reste inspirante et on peut tenter de se l’approprier pour bricoler quelque chose.
), mais l’idée générale reste inspirante et on peut tenter de se l’approprier pour bricoler quelque chose. 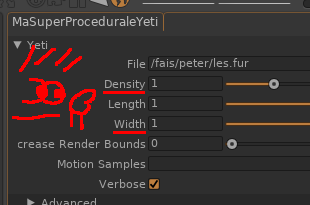


 ), on peut fabriquer une sphère et projeter chaque vertex via ce bout de code (honteusement inspiré de
), on peut fabriquer une sphère et projeter chaque vertex via ce bout de code (honteusement inspiré de 










 Bonjours, dans ce billet je vous propose de faire le tour de ce qu’on entend par LOD (Level Of Detail), en quoi ça consiste, à quoi ça sert, quand faut-il l’utiliser et quand vaut-il mieux s’en éloigner.
Bonjours, dans ce billet je vous propose de faire le tour de ce qu’on entend par LOD (Level Of Detail), en quoi ça consiste, à quoi ça sert, quand faut-il l’utiliser et quand vaut-il mieux s’en éloigner.





 Si vous utilisez
Si vous utilisez 