Mise à jour
Mise à jour de la base de données, veuillez patienter...
Site original : Sam & Max: Python, Django, Git et du cul
Des mois et des mois que je n’ai pas écrit :) Je ne compte même pas Max, qui a l’heure où je vous parle est en train découvrir les joies de la sidérurgie et qui ne se souvient du blog que quand on en parle dans le jacuzzi d’un FKK.
Ça va faire 4 ans qu’on a ce truc.
Entre temps lui et moi avont déménagé plusieurs fois, séparément, puis réaménagé ensemble, on a pris des responsabilités comme l’achat d’une machine a glaçon et la culture de plantes carnivores (la mienne est morte, mais il a la main verte apparemment).
Je vais être franc avec vous, l’écriture ne m’a pas manqué. Pas du tout.
Et puis aujourd’hui, j’ai eu envie. Ça ne m’avait pas pris depuis pas mal de temps, mais c’est une bonne chose : le sens du devoir avait depuis longtemps perdu son influence sur ma motivation éditoriale.
Est-ce que ça va durer un article ? 10 ? Un an ?
On va voir.
Mais ce ne sont pas les sujets qui manquent. En fait Python 3.6 est droit devant nous, avec plein de trucs chouettes à la clé. J’ai aussi beaucoup joué avec asyncio, jusqu’à trouver des bugs dedans et les reporter aux core-dev direct.
Pour le cul par contre, je ne sais pas encore, je vais laisser traîner jusqu’à ce que, tel Rocco dans Omar et Fred, ma bite me parle.
Python pour commencer donc.
Plein de changements de perfs, en vitesse, occupation mémoire, etc, prévus pour la prochaine version. Parmi eux, un changement majeur sur l’implémentation des dictionnaires inspiré directement de Pypy, qui les rendront plus compacts et plus rapides.
Et surtout, ordonnés par défaut.
Yep, plus besoin de collections.OrderedDict, qui restera malgré tout pour des raisons de compatibilité.
Enfin s’ils décident que ça fait maintenant partie de la specs et n’est pas juste un détail d’implémentation.
Ca veut dire aussi que **kwargs et __dict__ deviendront ordonnés, ce qui va arranger beaucoup de monde.
Mais l’article, en plus de prêcher la bonne nouvelle, est aussi la pour vous parler d’un petit hack sympa qui peut être pratique dans votre PYTHONSTARTUP pour des sessions shellifiantes : donner l’impression d’avoir un OrderedDict builtin par défaut.
from textwrap import dedent from collections import OrderedDict class OrderedDictFactory(object): # __getitem__ est la méthode magique appelée quand on fait objet[trucs] # et keys contient la liste des trucs def __getitem__(self, keys): for key in keys: # slice est un objet builtin fabriqué par Python quand on fait # objet[debut:fin], qui contient le debut et la fin if not isinstance(key, slice): # on check qu’on a bien une liste de slices raise SyntaxError(dedent(""" One element of the dict is not a key/value pair: {!r}. The syntax is d["key1": "value", "key2": "value", ...]. Check if you haven't missed a semicolon somewhere. """.format(key))) # et on retourne juste un ordered dict classique return OrderedDict([(k.start, k.stop) for k in keys]) # instance de référence pour notre factory abrégé pour des raisons de # facilité d = OrderedDictFactory() |
Et hop, on abuse la notation du slicing :
>>> menu = d[ "Samurai pizza cats" : "fruits de mer", # un slice "Tortue ninja" : "4 saisons", # un autre slice 'Max': "paysanne" # do you wanna slice ? ] >>> menu OrderedDict([('Samurai pizza cats', 'fruits de mer'), ('Tortues ninjsa', '4 saisons'), ('Max', 'paysanne')]) |
Rien à voir avec la choucroute, mais certaines personnes m’ont parlé de faire un miroir SFW du blog. Je vous rappelle que le blog est sous creative common, alors faites-vous plaiz, vous pouvez tout réutiliser.
collections.OrderedDict est une structure de données que j’utilise de plus en plus, surtout que sa réécriture en C en 3.5 lui donne des performances décentes.
Néanmoins, il n’y a pas dans l’API de moyen de récupérer le premier ou le dernier élément inséré dans dico. Il y a bien popitem(), mais ça retire l’élément du dictionnaire, et c’est pas forcément ce qu’on veut.
Heureusement OrderedDict est un itérable, et implémente __reversed__, et on peut donc utiliser les outils suivant our récupérer les extrémités avec une perf 0(1):
>>> from collections import OrderedDic >>> d = OrderedDict.fromkeys('azerty') >>> next(iter(d.items())) # premier élément 'a' >>> next(reversed(d.items())) # dernier élément 'y' |
Après l’implémentation de OrderedDict reste une liste doublement chainée, et on ne peut donc pas récupérer un élément à un index arbitraire sans le parcourir à la main…
J’en avais marre de taper Python en entier. Et surtout, je voulais lancer Python3.5 si il est dispo, et si possible ptpython, ou ipython. Sauf si je passe des arguments. Et que ça pete pas tout dans un virtualenv.
Bref:
function p { local SUFFIX="$@" if [[ "$VIRTUAL_ENV" != "" ]] then local PREFIX="$VIRTUAL_ENV"/bin COMMANDS=("python") else local PREFIX=/usr/bin COMMANDS=("python3.5" "python") fi if [[ "$#" -eq 0 ]]; then SUFFIX="" local COMMANDS=("python3.5 -m ptpython" "python3.5 -m ipython" "python -m ptpython" "python -m ipython" "python") fi for i in "${COMMANDS[@]}" do $PREFIX'/'$i $SUFFIX; [ "$?" -eq 0 ] && return 0 done } |
Quand le Divx est sorti, il y a eu tout un débat sur la valeur du DVD. Le truc qui prend de la place, qui s’abime, qui est une plaie à sauvegarder, qui est zoné… En prime, quand tu payais un DVD, tu avais ça:
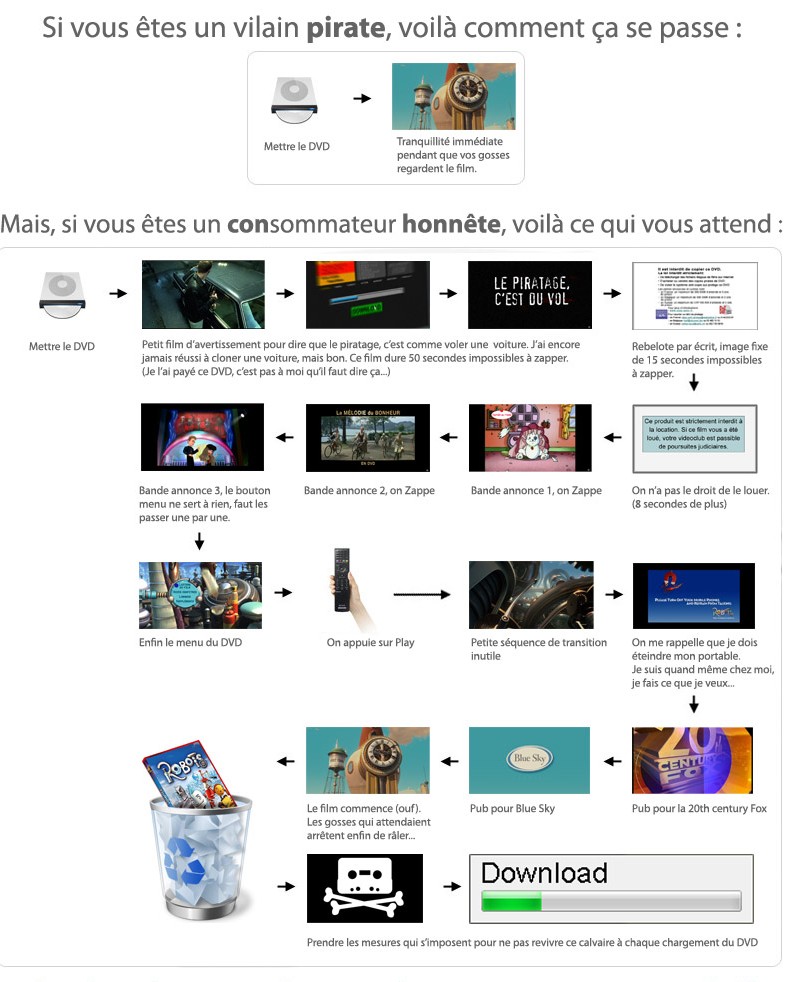
Attendez : il fallait aussi se déplacer pour acheter physiquement ce putain de DVD
Et est venu l’ère du streaming.
Et on a eu le droit à une redite.
Limite par pays, peu de sous-titre, catalogue limité et gros délais entre certaines sortis selon les médias et/ou les zones. Or the pirate bay et pop corn time n’ont pas tous ces problèmes.
Mais alors qu’en est-il du livre numérique ?
Le livre, c’est fait par des gens qui utilisent leur cerveau, non ?
Je veux dire, ils lisent, en théorie…
Et bien, après avoir galéré pour trouvé certains titres légalement et perdu ma collection suite au bricage de ma première tablette, je n’étais déjà pas très convaincu. J’aime l’outil pour le voyage, mais le service laisse à désirer. Nénamoins, je suis un geek, peut etre que les gens moins attachés à la cause étaient moins sensibles à ces problématiques.
Il faut croire que non, puisque mon frère m’a écrit dernièrement ce mail bien rageux:
ALORS j´ai acheté mon livre sur un site.
DRM ADOBE donc j´installe tout etc..1h30 à faire les inscriptions les mots de passe,
les confirmations. Et je peux même pas lire mon livre…
Les mecs sont les plus nazes de la terre ils se tirent un balle dans le pieds.Du coup je vais devoir pirater mon propre livre que j´ai acheté légalement
Youpi.
Et du coup bah qu´ils aillent bien se faire mettre pour la suite ce sera le premier et le dernier livre avec DRM que achète et si je trouve pas mon livre en Epub sans DRM bah je le piraterai.
Dés que j´ai mon livre sans DRM je te l´envois.
Bisoux
Notez que lui sait ce qu’est un DRM. Je n’ose pas imaginer Mme Michu.
Je travaille sur un projet magique. Chaque jour est une nouvelle découverte, une aventure !
Par exemple, c’est un projet utilisant l’exellent Django Rest Framework, une app Django très puissante qui permet de créer des API succulentes.
DRF est très flexible, et permet de régler tout un tas de paramètres à l’aide de classes de configuration. Par exemple, il extrait automatiquement tout champ lookup_field sur ses classes Serializer afin de choisir sur quel champ filtrer les données.
L’auteur du code que j’ai sous les yeux, je crois, a voulu être vraiment, mais alors vraiment sur d’avoir un look up:
class FooViewSet(ModelViewSet): class Meta: model = Foo lookup_field = 'pk' lookup_fields = ('pk', 'data_id') extra_lookup_fields = None |
En soit, c’est très drôle.
Et je pourrais arrêter l’article ici.
Mais non.
En effet, y a pas un truc qui vous choque ?
Je veux dire, autre que la sainte trinité des lookup fields…
Allez, relisez l’article depuis le début, je vous laisse une chance.
…
…
J’ai dis que DRF extraiyais un champ lookup_field sur les classes Serializer, et comme vous pouvez le constater, l’auteur ici hérite joyeusement de ModelViewSet, mais pas du tout de Serializer.
Oui, parce qu’on est en pleine exploration de Fistland (Au fond du fun !™), ces 3 champs ne sont en aucun cas exploités automatiquement par DRF… car sur les Viewset, lookup_field est utilisé pour générer des URLs, et mes prédécesseurs ont créé un router custo qui override ceci. Mais si on retire les champs, ça pête tout car ils y a des bouts de leur code qui supposent l’existence de ce champ.
Néanmoins, ne soyons pas complètement négatif, certaines classes héritent bien de Serialiser, et définissent aussi lookup_field. D’ailleurs une part de mon job est de migrer tout ça. Car la petite touche humoristique finale, c’est que lookup_field est deprecated depuis 3 releases dans DRF \o/ Mais deprecated sur les Serializer uniquement hein, pas les Viewset. Enfin je dis ça…