Statistiques du bac et web scraping
mercredi 19 juillet 2017 à 16:54Récemment, en voyant un article du Monde sur la répartition des mentions par rapport au prénom des bacheliers j’ai eu envie de faire pareil. Une façon intéressante de faire apparaître des tendances malheureusement facilement prévisibles.
J’ai donc pris Visual Studio Code et mon mal en patience et j’y suis allé. Comme je considère que ça pourrait être utile à des gens, voilà ma démarche, en intégralité.
Si la programmation ne vous intéresse pas, les résultats sont à la fin !
Récupération des liens
Bon, déjà, il faut savoir que personne ne propose de base de données des résultats. J’aurais pensé la trouver sur OpenData.gouv.fr mais il n’y a que les résultats des années précédentes et, en plus, dans des formats bizarres (mettre les résultats de 300 000 bacheliers dans une feuille Excel… ça semble pas une si bonne idée). Comme j’imagine qu’il faut demander ce genre d’informations à l’avance si on souhaite les publier sur son site (et motiver la demande), j’ai décidé de récupérer ces données moi-même.
Pour ça, je me suis tourné vers les nombreux sites qui proposent de connaître ses résultats. L’Etudiant, le Monde, beaucoup de sites de manière générale offrent ce service. Le problème, c’est qu’ils demandent souvent de faire une recherche précise (nom de famille et prénom, nom et académie, etc.) ce qui me prendrait énormément de temps à récupérer avec un script Python. Alors j’ai continué à chercher et j’ai trouvé Studyrama. Rien de particulier, si ce n’est qu’ils proposent une liste d’académie, puis une liste de noms triés par ordre alphabétique. Il ne me resterait donc qu’à récupérer la liste des académies, puis pour chaque académie, récupérer la liste des prénoms pour chaque lettre. C’est pas rien, mais ça se fait tranquillement avec Requests et BeautifulSoup. J’avais prévu de tout stocker dans une base de données SQLite (3).
Bon, alors, faire tout ça est bien gentil, mais ça demande d’y réfléchir un peu à l’avance. Comme je n’ai pas l’habitude de réfléchir, je n’ai pas réfléchi. Résultat : j’ai fait une table avec une colonne Académie et une colonne Lien. En effet, une fois qu’on a la liste de noms, on n’a pas encore les résultats, il faut aller sur une page réservée à chaque candidat pour obtenir les détails (série, mention…)
J’ai décidé de couper le travail en deux. D’abord, je récupérerai tous les liens des résultats, en parcourant d’abord la liste des académies, puis la liste alphabétique pour chaque lettre.
Dans un second temps, je récupérerais tous ces liens dans ma base de données et je parcourrais chacun pour obtenir les résultats précis.
Pourquoi ? C’est bien simple. On a environ 300 000 bacheliers. Récupérer vingt-six fois autant de pages qu’il y a d’académies en France peut se faire sans véritable problème (quelques minutes, vingt au maximum). En revanche, charger les résultats individuels de 300 000 personnes demande beaucoup plus de temps. Et garder un PC allumé assez de temps pour ça, se débrouiller pour ne pas avoir de coupure Internet (d’autant plus que ma box fait des caprices ces derniers temps) et surtout ne pas faire de modification dans le code se révèle assez compliqué. Donc je voulais avoir un programme qui me permettrait d’arrêter le scraping et de le reprendre quand je le veux. Mais on verra ça plus tard.
La récupération des différentes académies se fait sans aucune peine grâce à l’inspecteur de tout navigateur qui se respecte. On trouve la classe CSS ou l’ID qui va bien et la simplicité de Python couplée à la puissance de BeautifulSoup fait (presque) tout pour nous. On n’a plus qu’à stocker les données.
Récupération des résultats
Bon, on est content, on a toutes nos données. Encore une fois, grâce à notre ami Python et SQLite 3 on stocke tout sans aucun souci et on a nos données de première partie qui sont prêtes. Maintenant, récupérons les résultats.
Ici, l’idée est un peu plus compliquée. Je rappelle que j’ai dit que je voulais pouvoir arrêter la récupération des résultats pour la reprendre plus tard. Du coup… du coup j’ai fait une petite entourloupe qui fonctionne bien. Je précise que j’aurais pu résoudre cette entourloupe en concevant mieux ma base de données depuis le début mais honnêtement… tant pis, j’ai la flemme de corriger.
Au lancement du script, on récupère donc tous les liens qu’on a préparés dans la phase précédente. Puis, on créé une table Résultats dans laquelle iront tout naturellement les véritables résultats. Chaque résultat est identifiable de manière unique par son lien.
Remarque : comme je le craignais, Studyrama n’a pas cherché à avoir cette contrainte d’identification unique. Du coup, si jamais vous vous appelez “Alice Rousseaux” et que vous habitez en Ile de France, vous aurez un résultat de Schrödinger. Comme une autre personne s’appelle comme vous, vous ne saurez jamais si le résultat que Studyrama vous donne est le vôtre ou celui de l’autre Alice… Problème qui pourrait être résolu en demandant en plus la date de naissance, mais justement mon but c’était d’avoir toutes les données facilement. En résumé : il est possible qu’on ait quelques points en moins, mais sur un échantillon de 300 000 personnes… on fera sans.
On insère dans notre nouvelle table autant de lignes qu’on a de liens dans notre première table en remplissant les autres champs (Nom, Prénom, Résultat, Mention) par du vide. On ne peut que compléter l’académie de chaque lien puisqu’on l’a eue à la première étape.
Ensuite, toute l’astuce est là, on refait une sélection des lignes pas encore traitées en demandant à SQLite 3 un truc du genre SELECT Lien FROM Resultats WHERE Prenom = '' AND Nom = ''. C’est peut-être pas la meilleure façon, mais c’est plus simple et plus lisible que de faire une différence symétrique sur une jointure des deux tables. Et ça marche du premier coup.
Ensuite, la démarche est pas bien compliquée : on charge chaque lien de résultat, on l’analyse avec BeautifulSoup (on a vraiment beaucoup de chance : on dirait que Studyrama a tout fait pour que ses pages soient scrapables : par exemple le nom est dans un span séparé du prénom, il y a une classe pour chaque catégorie d’information… bref, c’est super facile).
Après l’analyse de chaque page, on UPDATE la ligne adaptée avec nos nouvelles informations.
En parallèle, on utilise un compteur (que j’ai appelé c) qui nous permet d’appeler db.commit() toutes les cinquante itérations pour sauvegarder nos modifications. Ainsi, si on arrête le script (par un Ctrl + C, une fermeture de console, un redémarrage, une perte de connexion Internet), on perd au maximum cinquante lignes, que l’on devra retélécharger à la prochaine exécution. Il faut juste trouver l’équilibre entre trop de commits (qui peuvent être lents) et pas assez de sauvegarde.
Visualisation des résultats
Voilà, là on arrive à la partie rigolote.
L’avantage, c’est que, comme je l’ai évoqué précédemment, on n’a pas besoin d’attendre que les résultats aient fini d’être téléchargés pour faire des tests sur nos données.
Mon premier objectif était de représenter la répartition des mentions très bien en fonction des prénoms (refaire un peu comme Le Monde mais à ma façon).
Il y a plusieurs façons de le faire, mais le plus important est de savoir éliminer les données induisant de l’erreur (facile) et ne pas en représenter trop, au risque de ne plus rien y voir (cf l’image d’en-dessous).
L’erreur
Pourquoi aurait-on de l’erreur ? C’est bien simple. Admettons qu’on prenne un bachelier au hasard, et qu’il s’appelle “Charles Philippe” (de son prénom). Il est le seul en France à s’appeler comme ça, résultat, s’il a eu mention très bien, on se retrouve avec 100% des Charles Philippe qui ont mention très bien. C’est une tendance qui a un intérêt limité puisque son erreur est assez grossière (ça paraît évident ; de manière plus formelle on peut dire que sur un échantillon de taille \(n\), on a une erreur en \(\frac{1}{\sqrt{n}}\), donc ici… une marge d’erreur de 100%… pas très beau à voir).
Pour résoudre ce problème, on se limite aux prénoms qui sont portés par au moins un certain nombre de gens. Régler ce paramètre est un peu ardu (il faut qu’il soit assez haut pour que les résultats ait du sens, mais assez bas pour que certains prénoms caractéristiques ne se voient pas virés alors qu’ils sont importants) mais ça se fait (grâce au hasard principalement).
La représentation
Le but est de représenter nos résultats sous forme de nuage de points, mais des points avec des légendes sur le graphique (oui parce que si on a cent couleurs différentes, lire la légende va pas être évident). Le problème, c’est qu’à part quelques prénoms qui se distinguent clairement (Emma est très porté et les Joséphine ont l’air plutôt douées avec plus d’un tiers de mention très bien), on se retrouve avec un gros pâté près de l’origine.
Pour résoudre ça (et comme je ne peux / veux pas partager d’image vectorielle ici) je réduis le nombre de points à représenter pour éviter l’effet pâté. Encore une fois, c’est une question de dosage. Mais si vous voulez avoir des données plus complètes, il suffit de lancer le script vous-même.
Pour faire tout ça d’un coup, j’utilise cette ligne absolument atroce :
for c, prenom in enumerate(reversed(sorted(tb.keys(), key = lambda x : tb[x]))):
c permet de compter les itérations et de s’arrêter au bon moment, le enumerate de faire apparaître le c, le reversed de parcourir notre liste dans le sens inverse pour avoir les plus grands pourcentages de mention très bien, le sorted permet de trier les prénoms par proportion de mention très bien. Un slicing aurait été sympa pour ajouter de l’exotisme à l’ensemble, mais on ne peut pas slicer sur un générateur 
annotate qui a l’avantage d’être simple et efficace.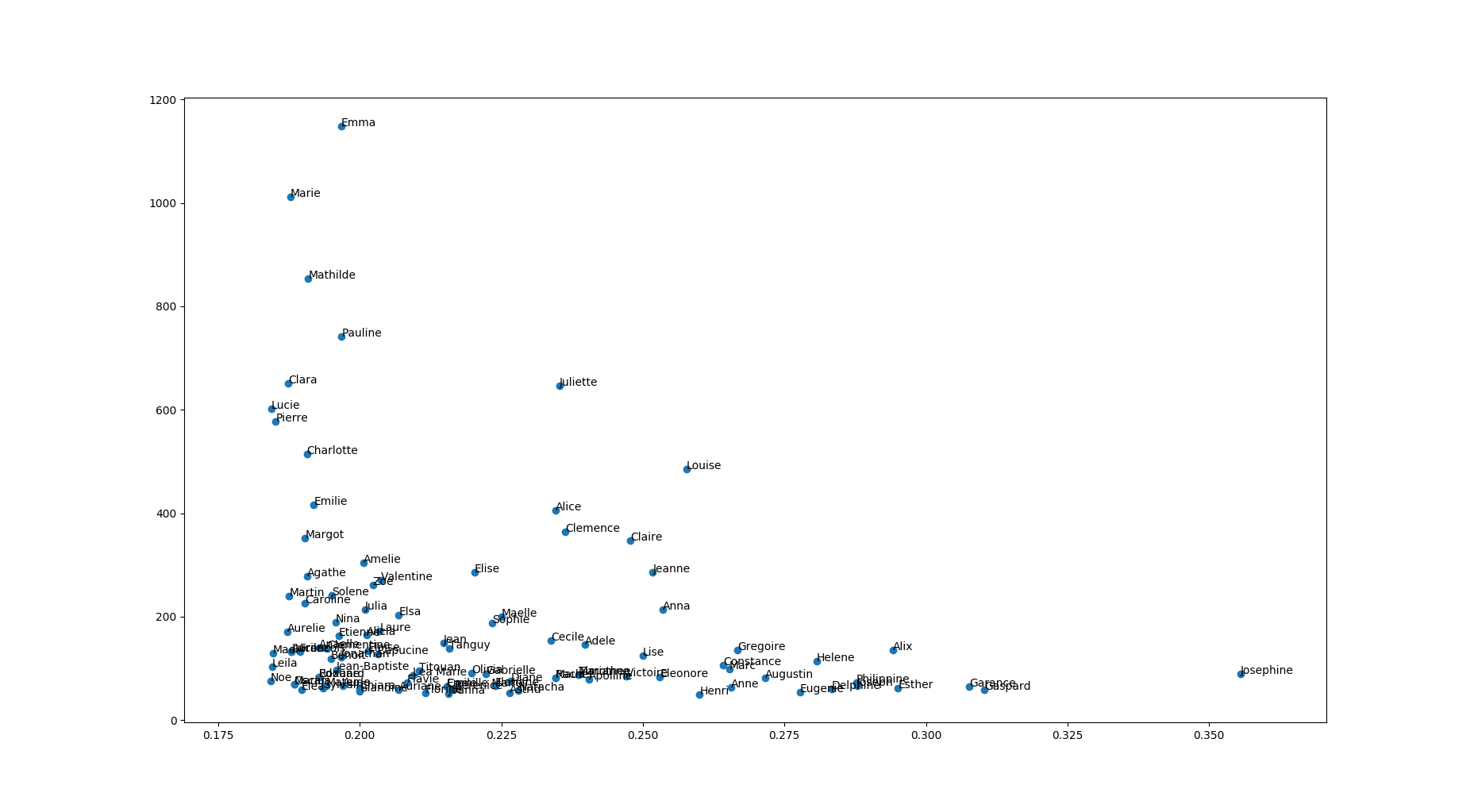 Cliquez sur l’image, sinon on voit rien.
Cliquez sur l’image, sinon on voit rien.
Autre résultat intéressant, les “sans mention”. En regardant qui sont les prénoms les plus “sans mentionnés” on voit bien que, quoi qu’en dise monsieur Macron, tout n’est pas qu’une question de volonté. Le milieu social aide un peu à la réussite ou à l’échec :
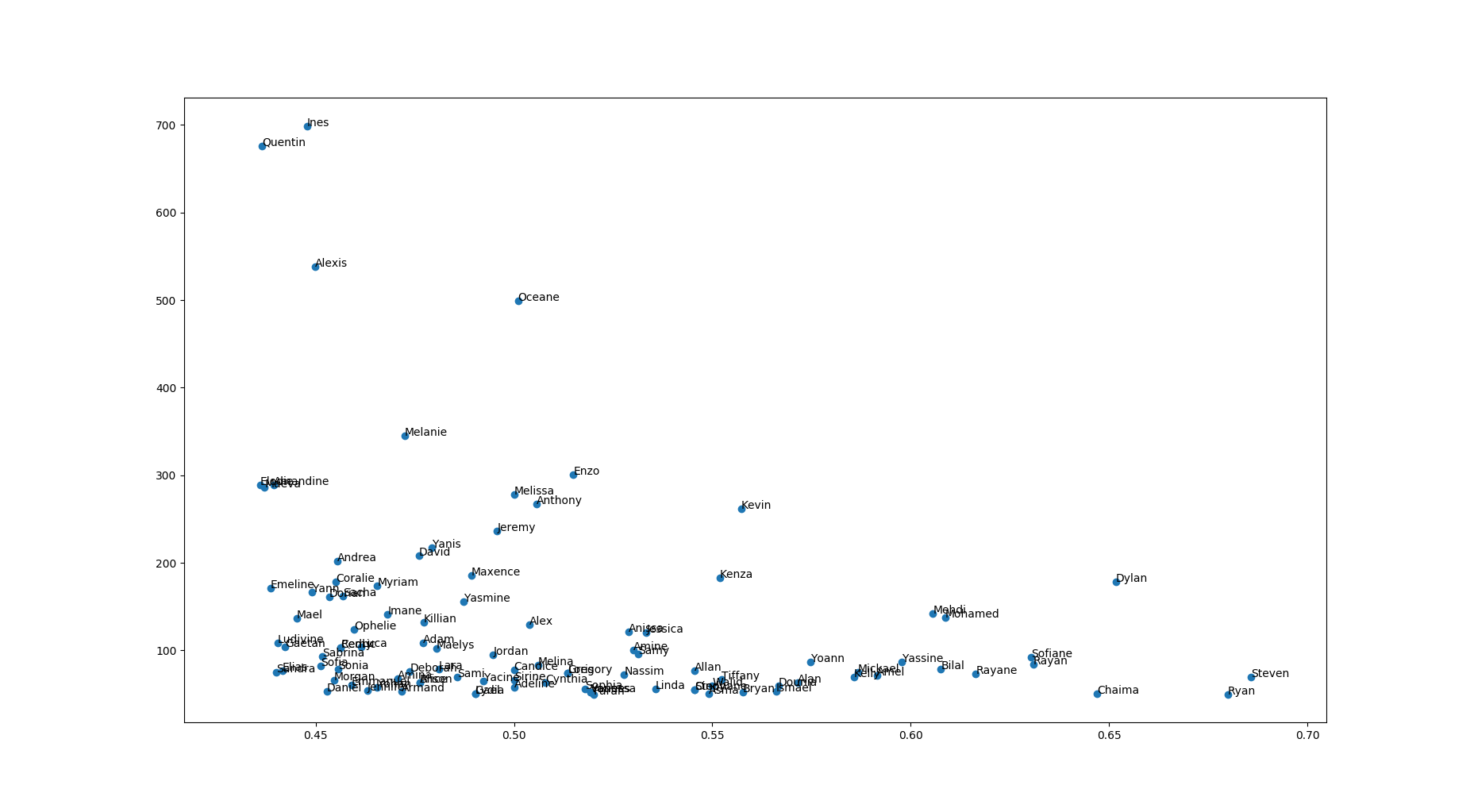
Notons tout de même que ces résultats sont toutes filières (générales) confondues. Il pourrait être intéressant de regarder la répartition des prénoms en fonction des filières (plus pour l’intérêt démographique de la répartition que pour les résultats au bac, qui doivent être sensiblement les mêmes quelle que soit la filière).
Voici le code pour cette première visualisation (ainsi que pour la récupération des données dans la BDD)
Pour ceux que ça intéresse, je mettrai un lien vers la base de données complète quand j’aurai terminé de récupérer tous les résultats.