Construire votre clavier en deux jours (ou presque)
vendredi 27 octobre 2017 à 18:09Des fois, on sait pas trop pourquoi, on se retrouve embarqué dans des projets un peu bizarres. Puis, avec du recul, on se demande bien ce qu’on y foutait. En tout cas ça m’arrive.
C’est comme ça qu’un jour je me suis dit “quand je serai en école d’ingénieur, je construirai un clavier mécanique à partir de rien, ce sera trop classe.”
Le temps, l’impatience et la dépression aidant, j’ai finalement pas réussi à attendre l’école d’ingénieur et je me suis lancé dans la construction d’un clavier mécanique en décembre dernier. Sans rien y connaître.
Un peu de contexte. A l’époque, j’avais un SteelSeries 6GV2, clavier fort agréable au demeurant, si ce n’est qu’il est avant tout fait pour jouer à des FPS (par ses switchs linéaires, mais je vais en reparler), et que jouer – à des FPS, ou à d’autre choses – en prépa, ça se fait peu. Comme, par contre, j’écrivais pas mal, bah mes petits doigts étaient rapidement fatigués.
J’avais donc le choix entre acheter un nouveau clavier (à terme, pas forcément immédiatement) et me faire le mien, sans trop tarder. Comme de toute façon ça allait me coûter de l’argent, autant le faire tout de suite. Et c’est ainsi qu’après une soirée de physique, je me suis retrouvé à acheter 110 switches sur eBay. Mais c’est quoi un switch ?
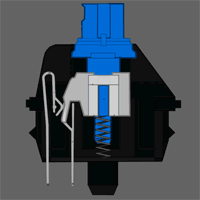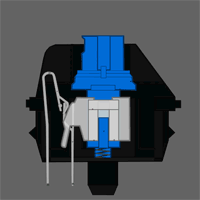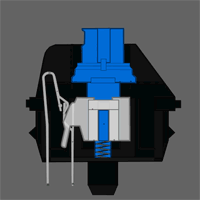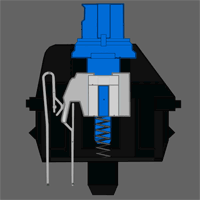 Petit brief. En effet, il existe deux types de claviers : les claviers classiques à dômes et les claviers mécaniques. Les seconds sont les claviers cool, les premiers sont les claviers chiants.
Petit brief. En effet, il existe deux types de claviers : les claviers classiques à dômes et les claviers mécaniques. Les seconds sont les claviers cool, les premiers sont les claviers chiants.
Dans un clavier à dômes, il y a plein de petits dômes en caoutchouc avec un peu de carbone sur le sommet, qui va compléter une piste –  elle aussi en carbone – quand vous appuyez dessus. Dans un clavier mécanique, il y a plein de petits interrupteurs, et dans l’idée ça marche pareil. Sauf que c’est bien plus agréable pour taper. L’avantage c’est que les switches peuvent également être de différents type : linéaires (c’est un ressort, et c’est tout : c’est très bien pour jouer à des jeux-vidéo où on veut au maximum que la sensation de frappe s’efface) ou à clic (c’est à dire qu’en appuyant le switch va passer un point où ça va faire clic et s’enfoncer tout seul : c’est très agréable pour taper). Chaque switch peut ensuite avoir différentes forces d’actuation (force nécessaire pour changer l’état physique de l’interrupteur) qui correspondent à si l’on devra appuyer plus ou moins fort.
elle aussi en carbone – quand vous appuyez dessus. Dans un clavier mécanique, il y a plein de petits interrupteurs, et dans l’idée ça marche pareil. Sauf que c’est bien plus agréable pour taper. L’avantage c’est que les switches peuvent également être de différents type : linéaires (c’est un ressort, et c’est tout : c’est très bien pour jouer à des jeux-vidéo où on veut au maximum que la sensation de frappe s’efface) ou à clic (c’est à dire qu’en appuyant le switch va passer un point où ça va faire clic et s’enfoncer tout seul : c’est très agréable pour taper). Chaque switch peut ensuite avoir différentes forces d’actuation (force nécessaire pour changer l’état physique de l’interrupteur) qui correspondent à si l’on devra appuyer plus ou moins fort.
Voilà l’idée. Sauf que, contrairement à ce qu’on pourrait penser, un clavier ce n’est pas si simple que ça à faire. Il suffit pas de connecter cent boutons.
Première étape : concevoir un layout
L’avantage, quand on fait son propre clavier – en entier – c’est qu’on peut disposer les trucs un peu comme on veut (voire même totalement comme on veut).
Mon objectif, d’une part, était de gagner de la place sur mon bureau (donc pas de clavier full avec pavé numérique). D’autre part, j’avais vraiment besoin des touches de navigation (flèches directionnelles et navigation dans la page), qui prennent beaucoup de place pour rien. Alors j’ai décidé de tout compresser.
Pour continuer, j’avais vraiment envie d’avoir quelque chose de plus : des touches pour des caractères spéciaux. Comme j’écrivais pas mal de maths à des endroits où on n’est pas censé écrire des maths (Discord, Facebook, etc.) j’avais besoin de caractères pas habituels qu’on ne trouvait pas facilement. Donc il fallait aussi trouver comment les placer, comme vous pouvez le voir.
Il existe un outil très pratique pour faire ça : Keyboard Layout Editor. (le mien est ici)

Je précise que ça ne se fait pas en deux jours. Parce que d’une part, il faut que ce soit à peu près rectangle (donc que ce soit droit sur tous les côtés) en prenant en compte le fait que toutes les touches ne font pas la même largeur, et ensuite parce qu’il faut également composer avec le matériel dont vous disposez, d’où la deuxième étape.
Deuxième étape : dépenser de l’argent (trop d’argent)
Je n’ai pas encore fait de liste de courses, mais en bref, il faut les composants suivants :
- Des switches (évidemment)
Le choix parmi toutes les sortes peut se révéler compliqué vu leur nombre et leur diversité, en fonction de l’usage final du clavier (jeu, transcription de rapports, les deux ?) et surtout vu leurs nombreuses marques différentes : Cherry MX, Alps, et tant d’autres.
J’ai opté pour des Gateron Blue : c’est à peu près la même chose que des Cherry MX Blue (c’est à dire non linéaire à clic très bruyant) mais c’est beaucoup moins cher et ça demande une force d’actuation (ce mot est vraiment français ?) moins grande, donc c’est moins fatiguant.
Où ? Partout,dans les villes, dans les campagnessur eBay, AliExpress à la limite. Si vous cherchez des Cherry MX, probablement dans des boutiques spécialisées. - Des touches
Comme taper sur des switches ne se révèle pas très pratique, on achète des touches. Là encore, il y a des pièges.
Déjà, il faut que les touches que vous achetez soient compatibles avec vos swtiches. Comme l’énorme majorité des switches sont soit des Cherry MX, soit compatibles, c’est généralement pas un problème. Si vous décidez d’utiliser des Alps ou des Torque, c’est votre problème.
Par contre, encore un piège (et c’est ce dont je parlais dans la partie layout) : une touche, ce n’est pas plat. Regardez votre clavier, vous verrez que toutes les touches ont une petite pente, ce qui permet d’être beaucoup plus agréable quand vous tapez. Ce qui veut dire que vous ne pouvez pas intervertir des touches de deux lignes différentes (ce qui rend la conception encore plus compliquée).
En plus, il faut faire attention que les touches soient bien étiquetées, histoire de pas récupérer des touches en russe (ça arrive pas mal). Comme les touches en français sont rares, que les faire graver c’est cher, et que je sais bien taper, j’en ai commandé des sans étiquettes. Comme ça si jamais j’ai besoin d’en échanger je peux le faire sans problème, et je me pose pas de question.
Où ? AliExpress est le meilleur chemin pour avoir un bon rapport qualité prix. Il existe des boutiques (en ligne) spécialisées dans les touches de clavier, avec des prix qui grimpent rapidement (de 5$ la touche à 300, en passant par 32…)

- Des diodes
Je ne vais pas détailler ici le fonctionnement électronique d’un clavier, si ça vous intéresse, d’autres l’ont déjà fait beaucoup mieux que je l’aurais fait.
Le fait est que pour permettre à votre clavier de disposer du N-Key-Rollover (ou NKRO) c’est à dire d’appuyer sur autant de touches que vous voulez en même temps, il faut que le courant ne passe dans les circuits que dans un sens (c’est pas tout à fait ça, mais c’est l’idée). Donc il faut des diodes.
Achetez-en donc deux cent sur AliExpress, comme des 1N4148
Attention je parle bien de diodes et pas de LED. On n’est pas encore à l’étape où on met des LED dans notre clavier, ça c’est pour le niveau supérieur. - Des plaques
C’est le moment où vous vous suicidez.

Troisième étape : la mort les plaques
Si vous êtes un être humain perspicace, vous aurez remarqué que, jusque-là, on a pas mal de composants intéressant, mais rien pour les tenir ensemble. Ce qui est plutôt ballot. C’est là qu’entre en jeu un élément important du clavier : le support.
Dans le cas où vous êtes, comme moi, limité par les moyens et par les connaissances en design de PCB (et le terme limité, dans mon cas, est un euphémisme) il faudra tout relier à la main (en vrai, ça se fait bien, sans devenir fou, avec un peu de patience et de musique). Mais la question n’est pas là.
L’idée est la suivante : quatre éléments, découpés dans ce que vous voulez (aluminium, inox, plastique, bois, MDF, chewing-gum) qui vous agir de la façon suivante.
- La plaque de base est juste un rectangle avec des trous dans les coins et un peu sur la longueur. (d’épaisseur adéquate pour pas qu’elle se plie, mais sans être trop épaisse).
- La première couche est un cadre relativement épais, avec aux mêmes emplacements des trous un peu plus larges. En plus, on rajoute un trou centré – ou pas – d’où on fera sortir un câble USB.
- La seconde couche est la même chose, sans le trou pour le câble USB.
- La switch plate est le même rectangle qu’en bas, avec des trous aux emplacements des switches. Et des trous aux mêmes endroits, mais larges comme sur la plaque de base.
Ensuite, on assemble le tout avec des vis et des entretoises. Et là, on remercie l’inventeur de l’entretoise. Parce qu’avec nos entretoises dans les couches intermédiaires, on peut visser les plaques haute et basse pour que l’ensemble fasse une boîte relativement compacte et qui tient bah heu… d’un tenant (David Tenant… aha.)
Vous allez me dire “jusque-là, rien de bien méchant !” Ah ah. C’est beau la naïveté. La vraie question c’est : mais comment qu’on fait ces plaques ?
Deux solutions : soit tout concevoir avec AutoCAD (j’ai essayé, j’ai échoué), soit générer un fichier DXF avec le générateur de SwillKB (en lui donnant votre fichier de Keyboard Layout Generator).
“Mais Thomas, c’est toujours pas très dur !”
Ce qui est dur, en fait, c’est quand vous avez fait tout ça et que vous vous demandez bien qui va vous fournir ces pièces. Généralement, à moins de disposer d’un fablab bien équipé pas loin de chez vous, vous risquez de ne pas pouvoir faire ça vous-même. Et ça va donc engendrer des… des frais.
Pour moi, environ soixante euros (après truandage et réductions), tout ça pour avoir deux plaques en acier inoxydable brossé découpées et deux cadres non pas en inox mais en plastique (il faut pas pousser mémé non plus).
Quatrième étape : l’attente
Alors là vous vous dites “ça y est ! on va recevoir nos pièces, on va monter notre clavier et écrire super bien !” mais non. Non, non, non.
Ca relève peut-être de l’exception, mais j’ai pas eu de chance quant à la découpe de mes pièces.
J’ai tout fait faire par Sculpteo. C’est une entreprise américaine implantée à Villejuif qui fait de la découpe, de l’impression 3D et ce genre de choses à des prix qui ne défient aucune concurrence. Mais ils sont plus ou moins seuls sur le marché, parce que les autres ne proposent généralement qu’un type de matériau (métal ou plastique mais pas les deux) et que ça devient cher en frais de port. Sinon, il y a John Steel (des alsaciens) et LaserGist (des grecs). Je vous laisse faire vos recherches.
Sauf que, Sculpteo a pas dû m’aimer puisque j’ai reçu la première fois mes cadres en plastique cassés (bon, la conception était pas ouf non plus puisque j’avais pas bien pris en compte la taille de la saillie pour la découpe de morceaux aussi épais, mais heu quand même) et surtout des plaques en métal pas alignées. Alors pour visser des trucs je vous laisse imaginer.

J’ai donc dû renvoyer tout le matériel et attendre une deuxième version.
La deuxième fois, j’ai reçu des cadres en plastique en bon état, et mieux protégés, mais des plaques en métal moins alignées que la première fois. J’étais un peu colère, mais j’ai quand même re-renvoyé mes pièces (de toute façon, j’avais pas trop le choix…)
Quand, enfin, j’ai re-re-reçu mes pièces, elles étaient cette fois en un morceau et alignées. Enfin alignées, ou presque, mais bon j’avais pas trop envie de leur refaire faire un aller-retour.
Le problème, le vrai, c’est qu’entre le moment où j’ai effectué la première commande et où j’ai reçu des pièces correctes, il s’est passé environ deux mois, les délais de livraison de renvoi, d’admission de leur part qu’ils s’étaient ratés et de “on se prépare à exécuter votre commande” aidant.
Bref.
Mais ça rend quand même bien !
Cinquième étape : être patient
Maintenant que vous avez toutes vos pièces, tous vos composants et surtout tout votre courage, on va passer à la partie pratique.
 Je ne l’ai pas précisé avant, mais il nous faut un point central dans ce clavier, et ce point central, de manière relativement standard, c’est un PJRC Teensy. C’est un microcontrôleur excessivement cher pour ce que c’est, mais c’est le seul qui puisse gérer autant d’entrées / sorties (pour un clavier plus petit, un Sparkfun Pro Micro, qui existe en version générique sur AliExpress, serait utilisable ; juste une remarque comme ça). Donc, heu, il en faudra un.
Je ne l’ai pas précisé avant, mais il nous faut un point central dans ce clavier, et ce point central, de manière relativement standard, c’est un PJRC Teensy. C’est un microcontrôleur excessivement cher pour ce que c’est, mais c’est le seul qui puisse gérer autant d’entrées / sorties (pour un clavier plus petit, un Sparkfun Pro Micro, qui existe en version générique sur AliExpress, serait utilisable ; juste une remarque comme ça). Donc, heu, il en faudra un.
Qu’est ce qui nous attend, donc ?
Déjà, il va éventuellement falloir coller tous vos switches dans votre plaque à switches.
Ensuite, il faudra souder des diodes entre chaque switch.
Puis, on rajoutera des câbles dans l’autre sens que les diodes (il va falloir les découper pile à la bonne taille, vous allez voir c’est pas du tout relou).
Après, on rajoutera des câbles depuis le début et la fin des lignes et des colonnes jusqu’au microcontrôleur. Ça c’est chiant.
Et pour finir, on ira faire une prière pour ne pas avoir fait de bêtise (dans mon cas, la prière n’a pas été suffisante).
C’est parti.
 Voilà, ça c’est le résultat final.
Voilà, ça c’est le résultat final.
Petite note pratique : il est conseillé, si vous faites une boîte faite de près ou de loin en métal, d’isoler le circuit de la plaque (sinon y’a moyen de faire du mal non seulement au clavier, mais aussi à votre port USB sur lequel il est branché). Pour cela, j’ai acheté du plastique pour couvrir les livres de cours que j’ai collé sur la plaque inférieure. Ça marche très bien.
Sixième étape : le firmware
Pour le firmware, je me suis basé sur QMK Firmware, un programme très complet qui sert de firmware à pas mal de claviers mécaniques personnalisés. Je ne détaillerai pas plus que ça, puisqu’un exemple dans ce cas-là va très bien :
Je précise que cette étape est relativement pas pratique si vous êtes sous Windows, puisque tout se compile sous Linux. Depuis Windows 10, vous pouvez utiliser le bash intégré à Windows (qu’il faut activer dans les paramètres) pour installer gcc et les outils nécessaires à la compilation et faire tout ça sans dual boot ou deuxième ordinateur mais ça reste peu pratique. Cependant ça se fait bien si on reste concentré.
Etape n : six mois plus tard
Déjà, je vous ferai remarquer que si Rome ne s’est pas construite en deux jours, ce clavier non plus. Parce que j’ai fait l’erreur de penser que tout se passerait comme prévu – ce qui, évidemment, ne pouvait pas être le cas.

Mais à part ça, je dois dire que j’en suis extrêmement convaincu.
Il est très confortable (les switches Gateron demandent moins de force que les Cherry MX, donc c’est super agréable de taper dessus), il est honnêtement relativement beau (j’aime beaucoup le style rouge / inox argenté) et surtout je suis le seul à pouvoir taper dessus parce que généralement, les touches sans lettre dessus ça déstabilise les gens.
En plus, mes apports personnels (qui ont eu du mal à fonctionner au début, comme les symboles mathématiques et l’entrée Unicode de manière générale) en font un clavier bien meilleur que la moyenne, et même que la plupart des claviers “personnalisables” (qui permettent d’enregistrer des macros et de personnaliser les touches).
Bref, si c’était à refaire… je le referais. Je changerais quelques trucs (notamment la façon dont je me débrouille pour la boîte, je pense que ce serait plus facile de m’adapter à un format classique, et ce serait surtout moins cher), mais je resterais sur les mêmes switches et surtout sur la méthode de soudure à la main (parce que c’est quand même très satisfaisant de se dire qu’on a fait tout ça tout seul).
En plus, dire qu’on a construit son clavier fait généralement son petit effet, et les gens m’ont jusque-là dit qu’ils le trouvaient vraiment bien (hormis bien sûr le fait qu’il manque les étiquettes sur les touches, mais bon, on sait taper ou on sait pas).