Les groupes de job par utilisateur
dimanche 5 février 2023 à 13:43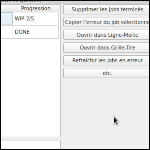 …pour sauver ta prod et faire ton bonheur.
…pour sauver ta prod et faire ton bonheur. 
Dans ce billet, nous allons parler d’un système permettant de résoudre un problème récurent de suivi asynchrone, côté utilisateur.
Bon, une explication aussi générique que ça ne vous avance pas des masses… Donc on va le dire autrement :
Quand un graphiste publie sa scène, il n’est pas rare de vouloir lancer un certain nombre de choses immédiatement après la publication, sans le bloquer. S’ensuit un torrent de propositions plus archaïque les unes que les autres pour ne serait-ce que définir le problème : Bienvenue dans le monde magique de l’asynchronie ! 
Mais putain, Dorian, tu vas encore faire un billet beaucoup trop long avec des termes super générique qui raconte rien ! J’ai des graphistes à aider, moi !
Ne vous inquiétez pas, on va essayer d’aller à l’essentiel.
Le problème
On va être très concret, et lister quelques problèmes récurrents :
- Quand un modeleur publie son travail, on peut vouloir exporter ses modés/son décor dans la foulée, sans bloquer son Maya.
- Quand un layouteur/animateur publie son travail, il est intéressant d’enchainer avec quelque chose derrière. Ça peut être un playblast ou un export alembic/USD, sans bloquer son Maya.
Plus un pipeline fait de choses pour délester le graphiste, plus cette question se pose. 
Il y a un paquet d’options disponibles ; Ouvrir un terminal, un subprocess Maya, passer par un microservice (qui ouvre Maya, bien joué, Roger !  ), etc.
), etc.
Elles sont toutes assez limitées ; Sature la RAM locale, le message d’erreur dans le terminal n’est pas lu/remonté, Maya crash en fond et les microservices c’est opaque pour l’utilisateur.
Le problème est tellement difficile à gérer qu’il n’est pas rare que tout le monde abandonne et choisissent de bloquer le graphiste qui « en profitera pour faire une pause café ». Bon, je sais qu’un graphiste qui boit du café c’est important pour la productivité, mais un lead/sup peut être amené à publier énormément de choses sur des scènes problématiques, et ça serait vraiment con que votre lead modé fasse un arrêt en publiant sa cinquantième retake de brins d’herbe… 
Abrège, Dorian…
En gros soit le graphiste ne voit rien, soit il perd du temps. Et je ne parle même pas d’isoler un crash (je sais, je sais, les scripts ne sont pas supposés planter, mais dès que ton input c’est une scène faite par un humain, c’est dogmatique de penser que tout va rouler).
Notez que parmi les options disponibles, je n’ai pas parlé de la farm : On pourrait parfaitement publier la scène puis envoyer une série de job sur la farm pour faire le boulot. 
Le problème est que l’utilisateur ne voit pas ce qui s’y passe et les UI de farm sont souvent imbitables. Et c’est le début de la solution que je propose. 
La solution
Le problème de la farm, on l’a vu, c’est que personne ne la regarde parce que :
- La UI souvent lourde.
- C’est le bordel.
- La UI est souvent moche.
- C’est le bordel.
Pourtant, la farm est surement le moyen de plus simple de garder un job qui échoue tout en permettant de reproduire le problème (et si vos jobs ont des effets de bords, je vous invite à lire mes deux billets sur le sujet  ).
).
L’approche présentée plus bas part du principe qu’on peut résoudre ces problèmes de façon pragmatique, sans demander un effort de dev trop important ; vous vous doutez que si j’en parle, c’est que j’ai déjà utilisé un mécanisme similaire et que ça fonctionnait. 
L’idée est donc de permettre à l’utilisateur de suivre les jobs qu’il envoie, sans lui exposer le détail des jobs en question ; autres que wip/done/pending.
Quel que soit votre système de farm, chaque job a un identifiant. Quelle que soit la tache à faire, il est rare qu’un seul job suffise. Pour un simple playblast, vous aurez souvent la génération des images depuis Maya, l’ajout de cartons et la génération du fichier vidéo.
On va grouper tous ces jobs dans un ensemble qu’on va appeler un job group. Et il va falloir stocker cette entrée dans une base de donnée dédiée (et non, bordel non : ShotGrid n’est pas une base de donnée dédiée, mais d’autres en parlent mieux que moi).
Pseudo-implémentation
Donc vous sortez votre base de donnée SQL préférée, et vous me créez une table dédiée :
- User id : Contiendra l’identifiant de l’utilisateur qui a envoyé le groupe de jobs.
- Label : Un petit texte faisant office de nom du groupe de jobs.
- Liste des job ids : Liste des identifiants des jobs du groupe.
Même pas besoin de mettre une clef primaire, c’est tellement magique !
Notez que certains gestionnaires de farm permettent déjà de grouper les jobs, il peut alors être pertinent de pointer vers l’id du groupe de job de votre gestionnaire de farm plutôt que faire la liste vous-même.
Faites un QTableWidget avec deux colonnes :
- Label
- Progress
Label affichera un très court descriptif du job group : « Playblast anim sq9999sh001 », « Export Alembic toto_001 sq9999sh001 ».
Progress affiche l’avancée générale des jobs : « WIP 2/5 », « DONE ».
Vous pouvez ajouter quelques boutons comme :
- Supprimer les jobs terminés.
- Copier l’erreur du job sélectionné.
- Ouvrir dans « gestionnaire de farm du studio ».
- etc.
Ça donne un truc comme ça :
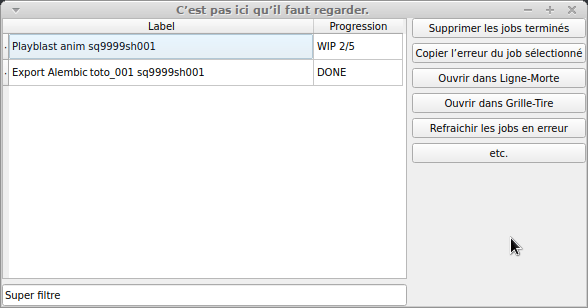
Designer est ton ami, mais j’y ai quand même passé beaucoup trop de temps. 
Et paf, vous avez une UI qui liste les jobs envoyé par l’utilisateur sous formes de groupes, les détails n’étant pas affichés. Ce n’est pas un bug, c’est une feature qui fait que votre UI n’est pas lourde ni repoussante.
Si vous avez suivi, vous comprendrez que la simplicité de cette UI lui permet de pouvoir être lancé depuis n’importe quel logiciel (e.g. juste après un publish) et est résolument tourné vers utilisateur qui peut maintenant publier à la chaine avant d’aller prendre sa pause café (notre problème original), et surtout, a enfin un moyen précis de communiquer sur ce qui est bloqué ou non, sans être dans le noir, tout en permettant aux TD/Wrangler de l’aider rapidement. 
Comme nous passons par une base de donnée dédiée, les job groups ne sont pas perdus après un redémarrage. 
Les requêtes à la farm peuvent être assez lourdes si on est bête (ce qui n’est surement pas votre cas, si vous lisez ce blog  ). Voici quelques idées pour améliorer l’implémentation :
). Voici quelques idées pour améliorer l’implémentation :
- Ne pas demander à la farm le status des jobs terminé (un flag dédié peut être mis dans la table job group pour ne faire aucun accès à la farm sur un groupe donné, considéré comme déjà terminé).
- Ne pas demander à la farm le status des jobs en erreur (un job peut rester des mois en erreur), mais ajouter un bouton « refresh erreur » pour permettre au graphiste de revérifier le job, après que le TD/wrangler ait résolu le souci.
- Diminuer l’intervalle des requêtes des status des jobs en attente (pending).
- Automatiquement supprimer les job groups terminés depuis X semaines (2, c’est pas mal). Ça peut être un cron.
Autre truc important : Cette UI doit pouvoir être lancé pour n’importe quel utilisateur (par une variable d’environnement, par exemple), pour simplifier le travail des TDs qui peut accéder directement aux problèmes de publish d’un graphiste sans lui demander quoi que ce soit. Ils peuvent même, dans la grâce éternelle qui les caractérise si bien, cliquer sur le « refresh erreur » à sa place.
Conclusion
Si vous n’êtes pas convaincu, c’est que vous manquez simplement d’ouverture d’esprit, vous avez tort, vous aimez Node.js, le chocolat aux raisins, Dieu, et vous êtes une personne méprisable qui aurait surement vendu sa grand-mère en 40.
Je ne vous félicite pas…
