Se protéger contre soi-même !
vendredi 8 novembre 2013 à 14:19Un accès au compte root, la commande rm disponible... Un mélange détonnant qui peut faire très mal. Ça sent l'erreur de manipulation de débutant tout ça !
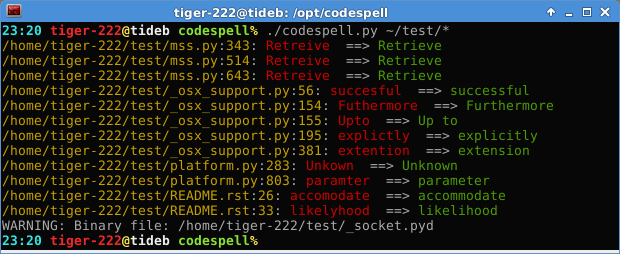
À fond dans mon nouveau projet, dont je vous parlerai plus tard, je dois supprimer les fichiers d'un répertoire. Si elle n'est pas belle celle-ci :
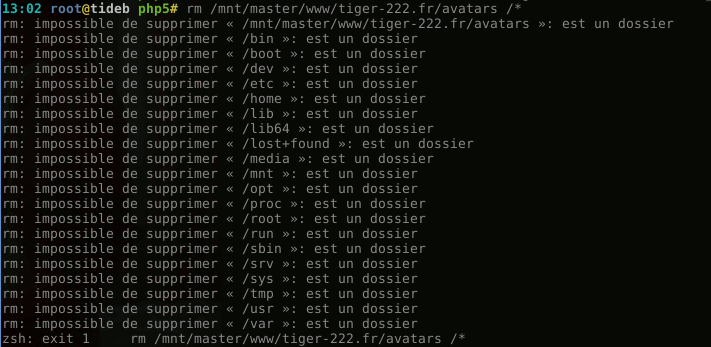
Putain ! Encore heureux que je n'avais pas utilisé l'argument
L'erreur à la con, ici, c'est que j'ai utilisé la touche TAB pour que Zsh complète le nom des chemins automatiquement. Vite fait, bien fait, ça aurait pu m'être fatal !
La synthèse de cette histoire : toujours faire attention.
La morale de cette histoire : toujours faire très attention.
La morale de cette morale : toujours faire super attention. TOUJOURS !
Et afin de me protéger (contre moi-même), un alias qui va bien :
À fond dans mon nouveau projet, dont je vous parlerai plus tard, je dois supprimer les fichiers d'un répertoire. Si elle n'est pas belle celle-ci :
Putain ! Encore heureux que je n'avais pas utilisé l'argument
-r ou --recursive ☠L'erreur à la con, ici, c'est que j'ai utilisé la touche TAB pour que Zsh complète le nom des chemins automatiquement. Vite fait, bien fait, ça aurait pu m'être fatal !
La synthèse de cette histoire : toujours faire attention.
La morale de cette histoire : toujours faire très attention.
La morale de cette morale : toujours faire super attention. TOUJOURS !
Et afin de me protéger (contre moi-même), un alias qui va bien :
alias rm='rm -Iv'-I est le mode intéractif. J'te jure, des fois... $#!°@☣